
시작하며
요즘 LLM 기반 서비스를 만들다 보면 에이전트, 툴 호출, 에이전틱 워크플로우, 온톨로지, 그래프 RAG 같은 용어를 자주 만나게 됩니다.
하지만 그보다 먼저 이해해야 할 기본 개념 중 하나가 바로 RAG입니다.
RAG는 오래된 개념처럼 보일 수 있지만, 여전히 LLM을 실무 시스템으로 만들 때 매우 중요한 구조입니다.
특히 모델이 모르는 정보를 어떻게 제공할 것인지, 최신 데이터나 내부 문서를 어떻게 활용할 것인지 고민한다면 RAG는 거의 반드시 등장합니다.
벡터 기반 RAG를 중심으로, RAG의 목적과 동작 방식, 임베딩, 벡터 DB, 청킹, 리랭킹, Query Transformation 같은 핵심 개념을 정리합니다.
1. RAG가 왜 필요한가요?
LLM은 많은 지식을 알고 있는 것처럼 보이지만, 기본적으로 몇 가지 한계를 가지고 있습니다.
첫째, 학습 시점 이후의 정보를 알지 못합니다.
모델이 학습된 이후에 생긴 정책, 제품, 문서, 장애 이력, 고객 데이터는 모델 내부에 존재하지 않습니다.
둘째, 회사 내부 문서나 개인 데이터는 알 수 없습니다.
사내 매뉴얼, 계약서, 고객 상담 이력, 운영 정책, 기술 가이드 같은 정보는 공개 학습 데이터에 포함되어 있지 않은 경우가 많습니다.
셋째, 모르는 내용도 그럴듯하게 말할 수 있습니다.
이것을 흔히 환각, 즉 hallucination이라고 부릅니다. 모델은 모르는 내용을 "모른다"고 하기보다, 그럴듯한 문장을 생성할 수 있습니다.
예를 들어 모델이 모르는 최신 서비스명이나 내부 프로젝트명을 물어보면, 실제로는 정보가 없는데도 마치 아는 것처럼 설명할 수 있습니다.
사용자:
두쫀쿠가 뭐야?
LLM:
두쫀쿠는 깊은 산속에 사는 희귀한 동물입니다.이 답변은 그럴듯해 보일 수 있지만, 근거가 없는 답변입니다.
RAG는 이런 문제를 줄이기 위해 등장한 방식입니다.
2. RAG란 무엇인가요?
RAG는 Retrieval-Augmented Generation의 약자입니다.
한국어로 표현하면 검색 증강 생성 또는 검색 기반 생성이라고 볼 수 있습니다.
핵심 아이디어는 간단합니다.
LLM이 답변하기 전에,
외부 문서에서 관련 정보를 먼저 검색하고,
그 정보를 참고해서 답변하게 합니다.즉, LLM에게 모든 것을 외우게 만드는 것이 아니라, 질문에 필요한 정보를 외부에서 찾아서 컨텍스트로 제공하는 방식입니다.
가장 기본적인 RAG 흐름은 다음과 같습니다.
사용자 질문(User Query)
↓
관련 문서 검색(Retrieval)
↓
검색 결과를 컨텍스트로 구성(Context)
↓
LLM 답변 생성(Generation)
예를 들어 사용자가 사내 휴가 정책을 물어본다고 가정해보겠습니다.
사용자 질문:
육아휴직 신청 절차를 알려주세요.
일반 LLM은 해당 회사의 내부 정책을 알 수 없습니다.
하지만 RAG 시스템은 먼저 사내 HR 문서에서 관련 내용을 검색합니다.
검색 결과:
- HR 정책 문서 > 육아휴직 신청 절차
- HR 정책 문서 > 휴직 신청 기한
- HR 정책 문서 > 필요 서류
그리고 이 검색 결과를 LLM에게 전달합니다.
아래 문서를 참고해서 답변하세요.
[검색된 HR 정책 문서 내용]
질문:
육아휴직 신청 절차를 알려주세요.이렇게 하면 LLM은 자신의 기억에 의존하는 것이 아니라, 검색된 문서를 근거로 답변할 수 있습니다.
3. 사실 우리는 이미 RAG를 하고 있었습니다
RAG라는 이름을 몰라도, 많은 사람은 이미 비슷한 방식을 사용해본 적이 있습니다.
예를 들어 ChatGPT에 문서를 붙여넣고 이렇게 요청한 경험이 있을 수 있습니다.
아래 내용을 참고해서 요약해줘.
[문서 내용 붙여넣기]
질문:
이 문서에서 중요한 정책 변경 사항은 뭐야?이것도 넓게 보면 RAG의 기본 아이디어와 같습니다.
다만 차이가 있습니다.
| 방식 | 설명 |
|---|---|
| 수동 방식 | 사람이 직접 문서를 찾아서 LLM에게 붙여넣습니다. |
| RAG 방식 | 시스템이 자동으로 관련 문서를 찾아서 LLM에게 제공합니다. |
즉, RAG는 사람이 하던 "문서 찾아서 붙여넣기"를 시스템화한 구조라고 볼 수 있습니다.
4. 왜 그냥 모든 문서를 LLM에게 넣으면 안 되나요?
이론적으로는 모든 문서를 LLM에게 넣고 답변하게 만들 수도 있습니다.
하지만 실제 서비스에서는 이 방식이 적합하지 않은 경우가 많습니다.
4.1 컨텍스트 길이에 한계가 있습니다
LLM은 한 번에 읽을 수 있는 토큰 수가 제한되어 있습니다.
문서가 수백 장, 수천 장이라면 모든 내용을 한 번에 넣기 어렵습니다.
4.2 비용이 증가합니다
관련 없는 문서까지 모두 넣으면 입력 토큰 수가 늘어납니다.
토큰 수가 늘어나면 비용이 증가하고, 응답 속도도 느려질 수 있습니다.
4.3 정확도가 떨어질 수 있습니다
문서가 많다고 항상 좋은 답변이 나오는 것은 아닙니다.
관련 없는 정보가 많이 섞이면 LLM이 중요한 근거를 놓치거나, 엉뚱한 내용을 참고할 수 있습니다.
따라서 중요한 것은 "문서를 많이 넣는 것"이 아니라, 질문에 필요한 문서만 정확히 찾아 넣는 것입니다.
전체 문서를 다 넣는 방식
→ 비용 증가, 노이즈 증가, 정확도 저하 가능성
관련 문서만 찾아 넣는 방식
→ 비용 절감, 노이즈 감소, 답변 근거 강화RAG의 목적은 바로 여기에 있습니다.
5. RAG를 시험공부에 비유하면
RAG는 시험 직전에 학생에게 요약노트를 주는 방식과 비슷합니다.
학생이 모든 교재를 처음부터 끝까지 외우고 있을 필요는 없습니다.
시험 문제가 나오면, 그 문제와 관련된 핵심 페이지를 찾아서 보여주면 됩니다.
학생은 그 내용을 참고해서 답안을 작성합니다.
전체 교재
↓
문제와 관련된 페이지 검색
↓
요약노트 구성
↓
답안 작성
RAG도 같은 방식으로 동작합니다.
전체 문서 저장소
↓
질문과 관련된 문서 조각 검색
↓
검색 결과를 프롬프트에 삽입
↓
LLM이 근거 기반 답변 생성이때 RAG의 품질은 "요약노트를 얼마나 잘 만들어주느냐"에 따라 달라집니다.
즉, 어떤 문서를 검색하고, 어떤 내용을 LLM에게 전달하는지가 매우 중요합니다.
6. Fine-tuning과 RAG의 차이
LLM에게 새로운 지식을 제공하는 방법으로는 크게 두 가지를 생각할 수 있습니다.
1. Fine-tuning
2. RAGFine-tuning은 모델 자체를 추가 학습시키는 방식입니다.
반면 RAG는 모델은 그대로 두고, 외부 지식을 검색해서 답변 시점에 제공하는 방식입니다.
| 구분 | Fine-tuning | RAG |
|---|---|---|
| 목적 | 모델의 행동 방식이나 특정 패턴 학습 | 외부 지식 참조 |
| 지식 업데이트 | 다시 학습이 필요할 수 있습니다 | 문서나 DB만 업데이트하면 됩니다 |
| 최신 정보 반영 | 상대적으로 어렵습니다 | 상대적으로 쉽습니다 |
| 내부 문서 활용 | 가능하지만 관리가 어렵습니다 | 매우 적합합니다 |
| 답변 근거 추적 | 어려울 수 있습니다 | 문서 출처를 연결하기 쉽습니다 |
| 주요 사용처 | 말투, 형식, 태스크 패턴 학습 | 사내 문서 QA, 정책 검색, 기술 문서 검색 |
RAG가 특히 적합한 상황은 다음과 같습니다.
최신 정보가 필요합니다.
사내 문서를 기반으로 답해야 합니다.
답변의 근거 문서를 함께 보여줘야 합니다.
문서가 자주 변경됩니다.
모델이 모르는 도메인 지식이 필요합니다.반대로 Fine-tuning이 더 적합한 경우도 있습니다.
답변 스타일을 고정하고 싶습니다.
특정 출력 형식을 안정적으로 만들고 싶습니다.
반복적인 태스크 패턴을 학습시키고 싶습니다.실무에서는 Fine-tuning과 RAG를 경쟁 관계로 보기보다, 서로 다른 문제를 해결하는 도구로 보는 것이 좋습니다.
7. 벡터 기반 RAG의 핵심은 Embedding입니다
RAG에서 가장 많이 사용되는 방식은 벡터 기반 검색(Vector Search) 입니다.
이를 이해하려면 먼저 임베딩(Embedding) 을 알아야 합니다.
임베딩은 텍스트를 숫자 벡터로 바꾸는 과정입니다.
예를 들어 다음 세 단어를 생각해보겠습니다.
개
고양이
아이폰사람은 자연스럽게 "개"와 "고양이"가 더 가깝다고 느낍니다.
둘 다 동물이라는 의미적 공통점이 있기 때문입니다.
임베딩 모델은 이런 의미적 유사성을 숫자 좌표로 표현합니다.
"개" → [0.12, -0.03, 0.88, ...]
"고양이" → [0.10, -0.01, 0.84, ...]
"아이폰" → [-0.72, 0.44, 0.05, ...]문장도 마찬가지입니다.
"SSO 설정 방법을 알려줘"
"통합 로그인 설정 가이드"
"SAML 인증 연동 문서"세 문장은 표현은 다르지만 의미적으로 관련이 있을 수 있습니다.
임베딩 모델은 이런 문장들을 벡터 공간 안에서 가까운 위치에 배치합니다.
즉, 임베딩은 텍스트의 의미를 숫자 공간 안에 배치하는 과정이라고 볼 수 있습니다.
8. Vector DB는 무엇인가요?
Vector DB는 임베딩된 벡터를 저장하고, 특정 질문과 가장 가까운 벡터를 빠르게 찾아주는 데이터베이스입니다.
일반적인 데이터베이스는 정확한 키워드나 조건으로 데이터를 찾습니다.
SELECT * FROM documents
WHERE title LIKE '%SSO%';반면 Vector DB는 의미적으로 가까운 데이터를 찾습니다.
사용자 질문:
통합 로그인 설정 방법 알려줘
검색 결과:
- SSO 설정 가이드
- SAML 연동 매뉴얼
- OIDC 인증 플로우사용자가 "SSO"라는 단어를 직접 쓰지 않아도, "통합 로그인"과 의미적으로 가까운 문서를 찾을 수 있습니다.
Vector DB는 대략 다음 역할을 합니다.
문서 조각 저장
문서 조각의 임베딩 저장
질문 임베딩과 가까운 문서 검색
유사도 기준으로 결과 정렬쉽게 말하면 Vector DB는 "의미가 비슷한 문서"를 찾아주는 저장소입니다.
참고로, 아래 배경도 함께 보면 Vector DB를 이해하기 쉽습니다. RAG에서 사용하는 Vector DB는 크게 세 가지 흐름이 합쳐진 결과로 볼 수 있습니다.
첫 번째는 1970년대 정보검색 분야의 Vector Space Model입니다. 이 모델은 문서와 사용자의 검색어를 벡터로 표현하고, 두 벡터의 유사도를 계산해 관련 문서를 찾는 방식입니다. 당시에는 지금처럼 딥러닝 embedding을 사용한 것은 아니고, 단어 빈도나 TF-IDF 같은 sparse vector를 주로 사용했습니다. 하지만 “문서와 query를 벡터 공간에 놓고, 가까운 것을 찾는다”는 핵심 아이디어는 지금의 Vector DB와 매우 유사합니다.
두 번째 전환점은 2013년 Google 연구진이 발표한 Word2Vec입니다. Word2Vec은 단어를 dense vector로 표현하는 방식을 대중화했습니다. 단어를 단순한 문자열이나 ID로 다루는 것이 아니라, 의미 관계가 반영된 벡터로 표현할 수 있다는 점을 보여주었습니다. 예를 들어 의미가 비슷한 단어들은 벡터 공간에서 가까운 위치에 놓이고, 단어 간 관계도 벡터 연산으로 어느 정도 표현될 수 있습니다.
다만 Word2Vec이 Vector DB 자체의 시작점은 아닙니다. Word2Vec은 데이터베이스가 아니라 embedding 모델입니다. 그러나 Word2Vec 이후 “텍스트의 의미를 벡터로 표현하고, 벡터 간 거리를 이용해 의미적으로 가까운 정보를 찾는다”는 사고방식이 널리 확산되었습니다. 이 흐름은 이후 문장 embedding, 문서 embedding, 이미지 embedding, multimodal embedding으로 확장되었습니다.
세 번째 흐름은 ANN, Approximate Nearest Neighbor 검색 기술의 발전입니다. embedding을 만들 수 있어도, 수백만 개나 수억 개의 벡터 중에서 가까운 벡터를 빠르게 찾지 못하면 실서비스에 사용하기 어렵습니다. 모든 벡터와 하나씩 거리를 계산하는 방식은 데이터가 커질수록 너무 느려지기 때문입니다. 이를 해결하기 위해 HNSW 같은 ANN 알고리즘과 FAISS 같은 벡터 검색 라이브러리가 발전했습니다. HNSW는 그래프 구조를 활용해 근접 벡터를 빠르게 찾는 방식이고, FAISS는 dense vector의 효율적인 similarity search와 clustering을 위한 대표적인 라이브러리입니다.9. 왜 벡터라고 부르나요?
임베딩 결과는 단순한 숫자 목록이 아니라, 고차원 공간 안의 좌표처럼 볼 수 있습니다. 각 텍스트는 벡터 공간 안의 한 점 또는 방향으로 표현됩니다.
두 문서가 얼마나 비슷한지 판단할 때는 보통 다음과 같은 기준을 사용합니다.
Cosine Similarity
Dot Product
Euclidean DistanceRAG에서 자주 언급되는 방식은 코사인 유사도(Cosine Similarity) 입니다.
코사인 유사도는 두 벡터의 방향이 얼마나 비슷한지 측정합니다.
즉, 두 텍스트가 같은 의미 방향을 가리키고 있는지를 보는 방식입니다.
방향이 비슷합니다.
→ 의미가 비슷할 가능성이 높습니다.
방향이 다릅니다.
→ 의미가 다를 가능성이 높습니다.그래서 벡터 기반 RAG에서는 질문과 문서를 모두 벡터로 바꾼 뒤, 질문 벡터와 가까운 문서 벡터를 검색합니다.
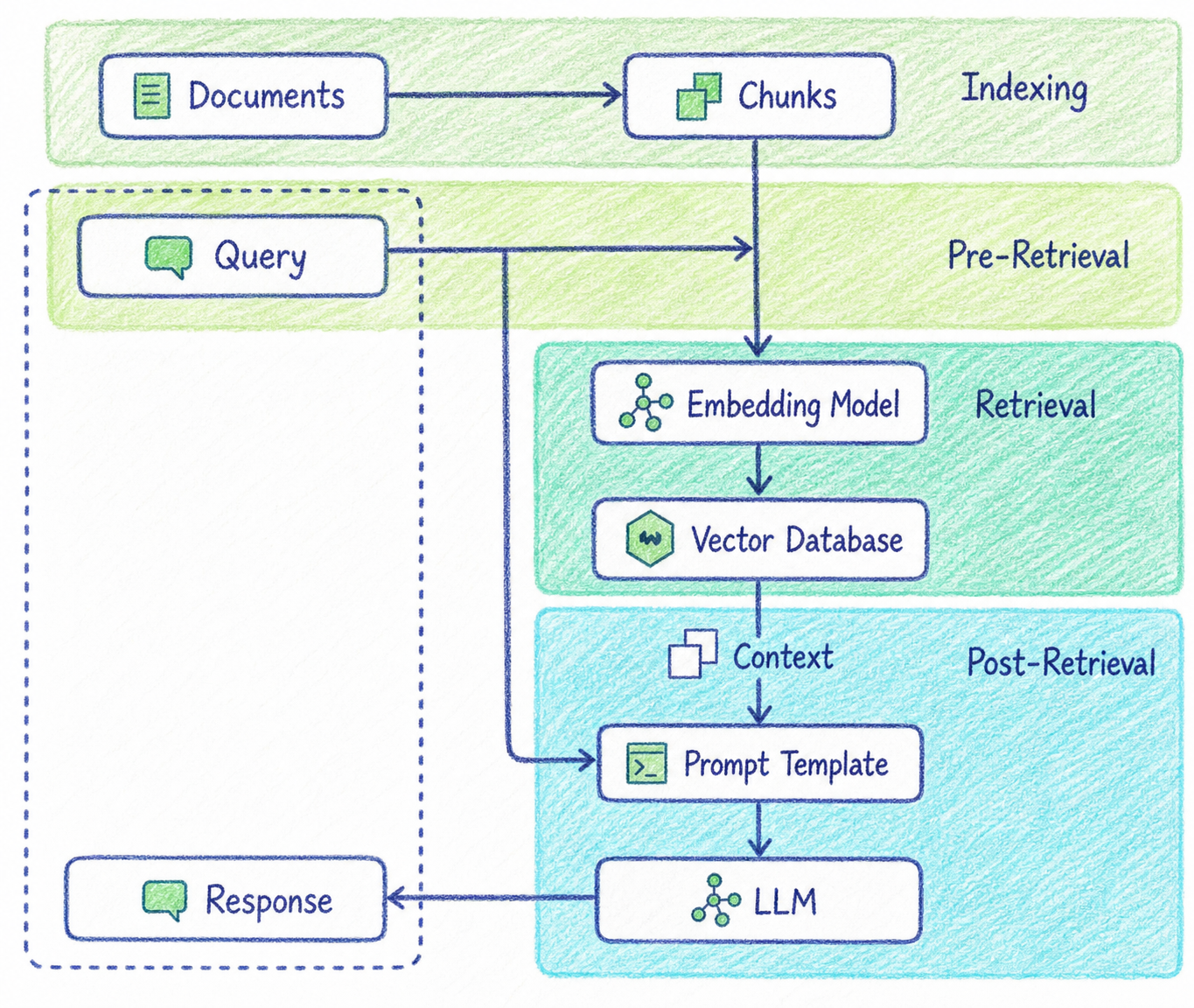
10. 벡터 기반 RAG의 전체 구조
벡터 기반 RAG는 크게 두 단계로 나눌 수 있습니다.
1. 인덱싱 단계(Indexing)
2. 질의 단계(Querying)10.1 인덱싱 단계
인덱싱은 문서를 미리 검색 가능한 형태로 준비하는 과정입니다.
원시 데이터(Raw Data)
↓
데이터 추출 및 파싱(Data Extraction & Parsing)
↓
데이터 정제(Data Cleaning)
↓
데이터 변환(Data Transformation)
↓
청크 분할(Chunking)
↓
임베딩 생성(Embedding)
↓
벡터 DB 저장(Vector Store)각 단계의 역할은 다음과 같습니다.
| 단계 | 설명 |
|---|---|
| 원시 데이터(Raw Data) | PDF, Word, HTML, DB, Markdown 등 원본 데이터입니다. |
| 데이터 추출 및 파싱(Data Extraction & Parsing) | 문서에서 텍스트, 표, 메타데이터를 추출하는 단계입니다. |
| 데이터 정제(Data Cleaning) | 불필요한 공백, 깨진 문자, 중복 텍스트를 제거하는 단계입니다. |
| 데이터 변환(Data Transformation) | 검색에 적합한 구조로 문서를 재구성하는 단계입니다. |
| 청크 분할(Chunking) | 긴 문서를 작은 단위로 나누는 단계입니다. |
| 임베딩 생성(Embedding) | 각 청크를 벡터로 변환하는 단계입니다. |
| 벡터 DB 저장(Vector Store) | 벡터와 원문, 메타데이터를 저장하는 단계입니다. |
여기서 특히 중요한 단계는 청크 분할(Chunking) 입니다.
문서를 너무 크게 나누면 검색 결과가 뭉뚱그려지고, 너무 작게 나누면 문맥이 사라질 수 있습니다.
10.2 질의 단계
질의 단계는 사용자의 질문이 들어왔을 때 실행되는 과정입니다.
사용자 질문(User Query)
↓
질문 변환(Query Transformation)
↓
질문 임베딩(Query Embedding)
↓
벡터 검색(Vector Search)
↓
검색 결과 재정렬(Reranking)
↓
컨텍스트 구성(Context Building)
↓
LLM 답변 생성(Generation)기본 RAG에서는 사용자의 질문을 그대로 임베딩해서 검색합니다.
하지만 실무에서는 질문을 바로 검색하지 않고, 먼저 검색에 적합한 형태로 다듬는 경우가 많습니다.
예를 들어 사용자가 이렇게 물을 수 있습니다.
이거 연동하는 방법 알려줘.이 질문만으로는 검색이 어렵습니다.
이전 대화에서 SSO를 이야기하고 있었다면, 검색용 질문은 다음처럼 바뀌어야 합니다.
SSO 연동 설정 방법이 과정이 Query Transformation입니다.
11. RAG에서 중요한 질문: 관련도란 무엇인가요?
RAG를 구현하면 곧바로 이런 질문을 마주하게 됩니다.
어떤 문서가 질문과 관련 있다고 볼 수 있을까요?단순 키워드 검색에서는 같은 단어가 많이 포함된 문서를 관련 문서로 봅니다.
하지만 벡터 검색에서는 의미적으로 가까운 문서를 관련 문서로 봅니다.
예를 들어 사용자가 이렇게 질문했다고 가정해보겠습니다.
통합 로그인 설정 방법 알려줘.문서에는 다음과 같이 적혀 있을 수 있습니다.
SSO 연동은 SAML 또는 OIDC 프로토콜을 통해 구성할 수 있습니다.키워드만 보면 "통합 로그인"이라는 단어가 없어서 이 문서를 놓칠 수 있습니다.
하지만 벡터 검색은 "통합 로그인", "SSO", "SAML", "OIDC"가 의미적으로 관련 있다는 점을 활용해 문서를 찾을 수 있습니다.
다만 벡터 검색도 완벽하지 않습니다.
예를 들어 다음 두 문장은 단어가 거의 비슷하지만 의미는 반대입니다.
철수와 영희는 계약을 체결했습니다.
철수와 영희는 계약을 체결하지 않았습니다.임베딩 모델은 이런 부정 표현이나 세부 조건을 항상 정확히 구분하지 못할 수 있습니다.
그래서 실무 RAG에서는 벡터 검색만 사용하지 않고, 여러 보완 기법을 함께 사용합니다.
12. RAG 고도화 기법
초기 RAG는 비교적 단순한 구조로 동작합니다.
질문 임베딩
↓
벡터 DB 검색
↓
상위 K개 문서 삽입
↓
답변 생성하지만 실제 서비스에서는 이것만으로 부족한 경우가 많습니다.
그래서 다양한 RAG 고도화 기법이 함께 사용됩니다.
12.1 Query Transformation
Query Transformation은 사용자의 질문을 검색에 적합한 형태로 재작성하는 과정입니다.
사용자의 질문은 대화체, 지시어, 생략어, 비공식 용어를 포함하는 경우가 많습니다.
사용자 질문:
이거 설정하는 법 알려줘.
변환된 검색 질의:
SSO 인증 설정 방법Query Transformation에서는 다음을 확인해야 합니다.
사용자의 질문이 검색에 충분히 명확한가요?
대화 맥락을 반영해야 하나요?
문서에서 사용하는 공식 용어로 변환할 필요가 있나요?
질문 재작성 과정에서 사용자의 의도가 왜곡되지는 않나요?예를 들어 사용자가 "이거"라고 말했을 때, 이전 대화에서 언급된 대상이 "SSO"라면 검색 질의는 "SSO 설정 방법"으로 바뀌어야 합니다.
반대로 맥락을 잘못 해석하면 전혀 다른 문서를 검색할 수 있으므로 주의해야 합니다.
12.2 Query Expansion
Query Expansion은 검색 성능을 높이기 위해 관련 키워드를 확장하는 과정입니다.
문서와 사용자의 용어가 다를 때 특히 유용합니다.
예를 들어 사용자는 "통합 로그인"이라고 묻지만, 문서에는 다음과 같은 용어가 사용될 수 있습니다.
SSO
Single Sign-On
SAML
OIDC
통합 인증
연합 인증이 경우 검색 질의를 확장하면 더 많은 관련 문서를 찾을 수 있습니다.
원래 질문:
통합 로그인 설정 방법
확장된 검색 질의:
통합 로그인, SSO, Single Sign-On, SAML, OIDC 설정 방법Query Expansion에서는 다음을 확인해야 합니다.
동의어, 약어, 영문명, 한글명이 함께 존재하나요?
확장이 검색 recall을 높이나요?
너무 많은 키워드가 추가되어 노이즈가 증가하지는 않나요?Query Transformation과 Query Expansion은 비슷해 보이지만 역할이 다릅니다.
Query Transformation
→ 질문을 검색하기 좋은 형태로 바꾸는 과정입니다.
Query Expansion
→ 검색에 도움이 되는 관련 키워드를 추가하는 과정입니다.12.3 Query Decomposition
Query Decomposition은 복잡한 질문을 여러 개의 작은 질문으로 나누는 과정입니다.
예를 들어 사용자가 이렇게 물었다고 가정해보겠습니다.
SSO 설정 방법과 장애 발생 시 확인해야 할 로그를 알려줘.이 질문은 두 가지 요구를 포함합니다.
1. SSO 설정 방법은 무엇인가요?
2. SSO 장애 발생 시 어떤 로그를 확인해야 하나요?각 질문을 따로 검색하면 더 정확한 문서를 찾을 수 있습니다.
원본 질문
↓
하위 질문 생성
↓
각 질문별 검색
↓
검색 결과 통합
↓
최종 답변 생성Query Decomposition은 특히 다음과 같은 질문에 유용합니다.
비교 질문
원인 분석 질문
여러 조건이 섞인 질문
복수 문서를 조합해야 하는 질문
정책과 예외 조건을 함께 확인해야 하는 질문예를 들어 다음 질문은 분해해서 처리하는 것이 좋습니다.
계약 해지 조건과 환불 가능 여부를 함께 알려주세요.분해하면 다음과 같습니다.
1. 계약 해지 조건은 무엇인가요?
2. 환불 가능 조건은 무엇인가요?
3. 해지 시 위약금 조항이 있나요?12.4 Query Routing
Query Routing은 질문을 적절한 데이터 소스나 검색기로 보내는 과정입니다.
RAG 시스템에 여러 데이터 소스가 있을 수 있습니다.
인사 문서
기술 문서
법무 문서
고객 상담 이력
상품 DB
SQL DB
외부 웹 검색사용자 질문에 따라 검색 위치가 달라져야 합니다.
육아휴직 신청 방법 알려줘.
→ 인사 문서 검색
API 인증 오류 해결 방법 알려줘.
→ 기술 문서 검색
지난달 매출 알려줘.
→ SQL DB 조회
계약 해지 조건 알려줘.
→ 법무 문서 검색라우팅이 없으면 모든 저장소를 무작정 검색하게 됩니다.
이 경우 관련 없는 문서가 많이 섞이고, 답변 품질이 떨어질 수 있습니다.
Query Routing에서는 다음을 확인해야 합니다.
질문 유형을 분류할 수 있나요?
데이터 소스가 여러 개인가요?
각 데이터 소스의 역할이 명확한가요?
잘못된 라우팅이 발생했을 때 fallback 전략이 있나요?12.5 Reranking
Reranking은 1차 검색 결과를 다시 정렬하는 과정입니다.
벡터 검색은 빠르게 후보 문서를 찾는 데 강점이 있습니다.
하지만 상위 결과가 항상 최적의 답변 근거라는 보장은 없습니다.
그래서 보통 다음 구조를 사용합니다.
벡터 검색으로 후보 20개 검색
↓
Reranker로 관련도 재평가
↓
상위 3~5개만 LLM에 전달Reranking은 RAG 품질을 높이는 데 매우 효과적인 단계입니다.
검색 결과는 나오지만 답변이 부정확하다면, 먼저 Reranking 적용을 검토할 수 있습니다.
12.6 Metadata Filtering
Metadata Filtering은 문서의 속성 정보를 활용해 검색 범위를 좁히는 방법입니다.
예를 들어 문서마다 다음과 같은 메타데이터를 붙일 수 있습니다.
문서 유형: 정책 / 매뉴얼 / FAQ / 회의록
부서: HR / Legal / Engineering / Sales
작성일: 2025-01-10
제품명: Product A
버전: v2.1
권한 등급: internal / confidential사용자가 "2025년 이후의 환불 정책"을 물었다면, 검색 전에 날짜와 문서 유형으로 필터링할 수 있습니다.
문서 유형 = 정책
작성일 >= 2025-01-01
검색어 = 환불 정책실무 RAG에서 메타데이터는 매우 중요합니다.
잘 설계된 메타데이터는 검색 품질을 높이고, 불필요한 문서 검색을 줄여줍니다.
13. RAG는 단순히 Vector DB를 붙이는 일이 아닙니다
요즘은 RAG를 시작하는 것 자체는 쉬워졌습니다.
문서를 넣습니다.
임베딩을 만듭니다.
Vector DB에 저장합니다.
질문이 들어오면 검색합니다.
검색 결과를 LLM에게 넣습니다.
하지만 실제로 쓸 만한 RAG를 만들려면 더 많은 고민이 필요합니다.
문서를 어떻게 파싱할 것인가요?
표와 이미지는 어떻게 처리할 것인가요?
청크 크기는 어떻게 정할 것인가요?
청크 간 overlap은 얼마나 줄 것인가요?
문서 제목과 계층 구조를 어떻게 보존할 것인가요?
메타데이터는 무엇을 붙일 것인가요?
검색 결과는 몇 개까지 가져올 것인가요?
벡터 검색과 키워드 검색을 함께 사용할 것인가요?
Reranking을 적용할 것인가요?
답변에 출처를 표시할 것인가요?
권한이 없는 문서는 검색되지 않게 할 것인가요?결국 좋은 RAG는 "LLM을 잘 쓰는 문제"이면서 동시에 "데이터를 잘 다루는 문제"입니다.
14. 좋은 RAG의 핵심은 데이터 이해입니다
RAG를 구축하다 보면 어느 순간 이런 질문을 하게 됩니다.
이 문서는 통째로 임베딩해야 하나요?
섹션 단위로 나눠야 하나요?
표는 행 단위로 나눠야 하나요?
요약본을 따로 만들어야 하나요?
문서의 제목을 청크마다 붙여야 하나요?
검색을 잘 되게 하려면 어떤 태그를 붙여야 하나요?이 구간부터는 단순 구현보다 데이터 설계가 중요해집니다. 문서 유형에 따라 청킹 전략도 달라져야 합니다.
정책 문서
정책 문서는 조항 단위로 나누는 것이 적합할 수 있습니다.
제1조 목적
제2조 정의
제3조 신청 조건
제4조 예외 사항기술 문서
기술 문서는 문제 해결 단위로 나누는 것이 좋을 수 있습니다.
증상
원인
해결 방법
관련 로그
참고 명령어15. Memory와 RAG는 구분하는 것이 좋습니다
에이전트 시스템에서는 Memory와 RAG가 함께 언급되는 경우가 많습니다.
하지만 둘은 목적이 다르기 때문에 구분해서 설계하는 것이 좋습니다.
| 구분 | Memory | RAG |
|---|---|---|
| 목적 | 사용자나 에이전트의 상태, 선호, 과거 행동 저장 | 외부 지식 문서 검색 |
| 데이터 성격 | 개인화된 경험, 대화 이력, 작업 상태 | 정책, 매뉴얼, 문서, DB |
| 변경 주체 | 에이전트 또는 사용자 | 문서 관리 시스템, 운영자 |
| 위험 | 잘못된 기억 누적 | 잘못된 문서 검색 |
| 예시 | 사용자는 Python을 선호합니다. | API 인증 방식은 OAuth2입니다. |
RAG 참조 문서를 에이전트가 마음대로 수정하게 만들면 운영 파이프라인이 복잡해질 수 있습니다.
문서 수정, 재파싱, 재청킹, 재임베딩, 인덱스 갱신, 권한 관리까지 고려해야 하기 때문입니다.
따라서 실무에서는 보통 다음처럼 구분하는 것이 안전합니다.
Memory
→ 사용자별 선호, 대화 맥락, 작업 상태
RAG Knowledge Base
→ 검증된 문서, 정책, 매뉴얼, 기술 자료16. RAG가 죽었다는 말에 대하여
LLM의 컨텍스트 길이가 길어지고, 에이전트와 툴 호출이 발전하면서 RAG가 필요 없는 것 아니냐는 이야기가 종종 나옵니다. 하지만 RAG의 본질은 사라지지 않습니다.
필요한 정보를 찾습니다.
관련 없는 정보를 줄입니다.
근거를 기반으로 답변합니다.
비용과 정확도를 관리합니다.컨텍스트가 길어져도 모든 데이터를 매번 다 넣는 것은 비효율적입니다.
에이전트가 발전해도 에이전트가 참조할 수 있는 신뢰 가능한 지식 저장소는 필요합니다.
툴 호출이 좋아져도 어떤 데이터를 가져와야 하는지 판단하는 검색 구조는 여전히 중요합니다.
RAG는 특정 유행 기술이라기보다, LLM 시스템에서 외부 지식을 다루는 기본 패턴에 가깝습니다.
17. RAG를 공부할 때 봐야 할 핵심 주제
RAG를 제대로 공부하려면 단순히 "Vector DB에 넣고 검색한다"에서 멈추면 안 됩니다.
아래 주제를 함께 이해해야 합니다.
문서 파싱(Document Parsing)
데이터 정제(Data Cleaning)
청킹 전략(Chunking Strategy)
임베딩 모델(Embedding Model)
벡터 검색(Vector Search)
하이브리드 검색(Hybrid Search)
메타데이터 필터링(Metadata Filtering)
쿼리 변환(Query Transformation)
쿼리 확장(Query Expansion)
쿼리 분해(Query Decomposition)
쿼리 라우팅(Query Routing)
리랭킹(Reranking)
컨텍스트 압축(Context Compression)
답변 근거 표시(Citation)
평가(Evaluation)
권한 관리(Access Control)특히 실무에서는 다음 세 가지가 중요합니다.
1. 데이터를 어떻게 나눌 것인가요?
2. 질문을 어떻게 검색 질의로 바꿀 것인가요?
3. 검색된 결과가 정말 답변에 필요한 근거인가요?
18. RAG 구현을 위한 기본 체크리스트
RAG 시스템을 만들 때는 아래 질문을 기준으로 점검할 수 있습니다.
데이터 준비
원본 문서의 형식은 무엇인가요?
PDF, HTML, Markdown, DB, Notion, Confluence 등 어디에서 가져오나요?
표, 이미지, 코드 블록은 어떻게 처리하나요?
중복 문서는 어떻게 제거하나요?
문서 업데이트 주기는 어떻게 관리하나요?
청킹
청크 크기는 적절한가요?
문맥이 끊기지 않나요?
제목, 섹션, 문서 경로가 청크에 포함되나요?
청크 overlap은 필요한가요?
문서 유형별로 다른 청킹 전략이 필요한가요?
임베딩
한국어 검색에 적합한 임베딩 모델인가요?
도메인 용어를 잘 표현하나요?
질문과 문서가 같은 언어로 임베딩되나요?
임베딩 모델 변경 시 재색인이 필요한가요?
검색
Top-K 값은 적절한가요?
벡터 검색만으로 충분한가요?
키워드 검색을 함께 사용해야 하나요?
메타데이터 필터링이 필요한가요?
검색 결과에 노이즈가 많지는 않나요?
생성
LLM에게 전달하는 컨텍스트가 충분한가요?
불필요한 문서가 너무 많이 들어가지는 않나요?
답변에 출처를 표시하나요?
모르는 경우 모른다고 답하게 하나요?
검색 결과에 없는 내용을 생성하지 않도록 제어하나요?
평가
정답 문서가 검색 결과 상위에 나오나요?
답변이 근거 문서와 일치하나요?
질문 유형별 실패 사례를 수집하고 있나요?
검색 실패와 생성 실패를 분리해서 분석하나요?
19. 정리

RAG는 LLM에게 모든 지식을 외우게 만드는 기술이 아닙니다. LLM이 답변하기 전에 필요한 정보를 찾아서 제공하는 구조입니다.
핵심 흐름은 단순합니다.
질문을 이해합니다.
관련 문서를 찾습니다.
필요한 문맥만 골라냅니다.
LLM에게 근거와 함께 답하게 합니다.
하지만 실제 품질은 세부 설계에서 달라집니다.
문서를 어떻게 파싱하나요?
청크를 어떻게 나누나요?
질문을 어떻게 변환하나요?
어떤 검색 방식을 사용하나요?
검색 결과를 어떻게 재정렬하나요?
LLM에게 어떤 컨텍스트를 넣나요?
답변이 근거에 기반하는지 어떻게 검증하나요?
결국 RAG의 목적은 하나입니다.
LLM이 더 정확하고,
더 최신이며,
더 근거 있는 답변을 하도록 돕는 것입니다.
RAG는 낡은 개념이라기보다, LLM을 실무 시스템으로 만들기 위한 기본 인프라에 가깝습니다. 에이전트, 툴 호출, 긴 컨텍스트, 온톨로지, 그래프 검색이 발전하더라도, 좋은 답변을 위해 필요한 정보를 찾아 넣는다는 RAG의 본질은 계속 남습니다.
'AI' 카테고리의 다른 글
| 지구상에서 가장 친절한 RAG 02: 청킹 전략은 왜 중요한가 (0) | 2026.06.03 |
|---|---|
| 지구상에서 가장 친절한 RAG 01: 데이터 전처리가 검색 품질을 결정하는 이유 (0) | 2026.06.03 |
| 클로드코드 스킬 실전 가이드: 에이전트에게 일하는 법 가르치기 (0) | 2026.05.30 |
| 싱글 에이전트, 멀티 에이전트 어느것을 선택해야할까? (0) | 2026.05.30 |
| n8n is dead? (0) | 2026.05.30 |