
1. 시작하며
RAG를 도입할 때 많은 사람들이 먼저 LLM 성능, 임베딩 모델, 벡터 데이터베이스, 프롬프트 최적화에 집중합니다. 물론 이 요소들도 중요합니다. 하지만 실제 RAG 시스템의 품질을 좌우하는 더 근본적인 요소가 있습니다. 바로 Data Pre-Processing, 즉 데이터 전처리입니다.
RAG는 외부 문서를 검색한 뒤, 검색된 정보를 LLM에 전달해 답변을 생성하는 방식입니다. 따라서 LLM이 아무리 좋아도 검색되는 데이터가 부정확하거나 지저분하면 좋은 답변을 만들기 어렵습니다. 결국 RAG의 답변 품질은 어떤 데이터를, 어떤 형태로, 얼마나 잘 검색 가능하게 만들었는지에 따라 결과가 결정됩니다.
전체 흐름
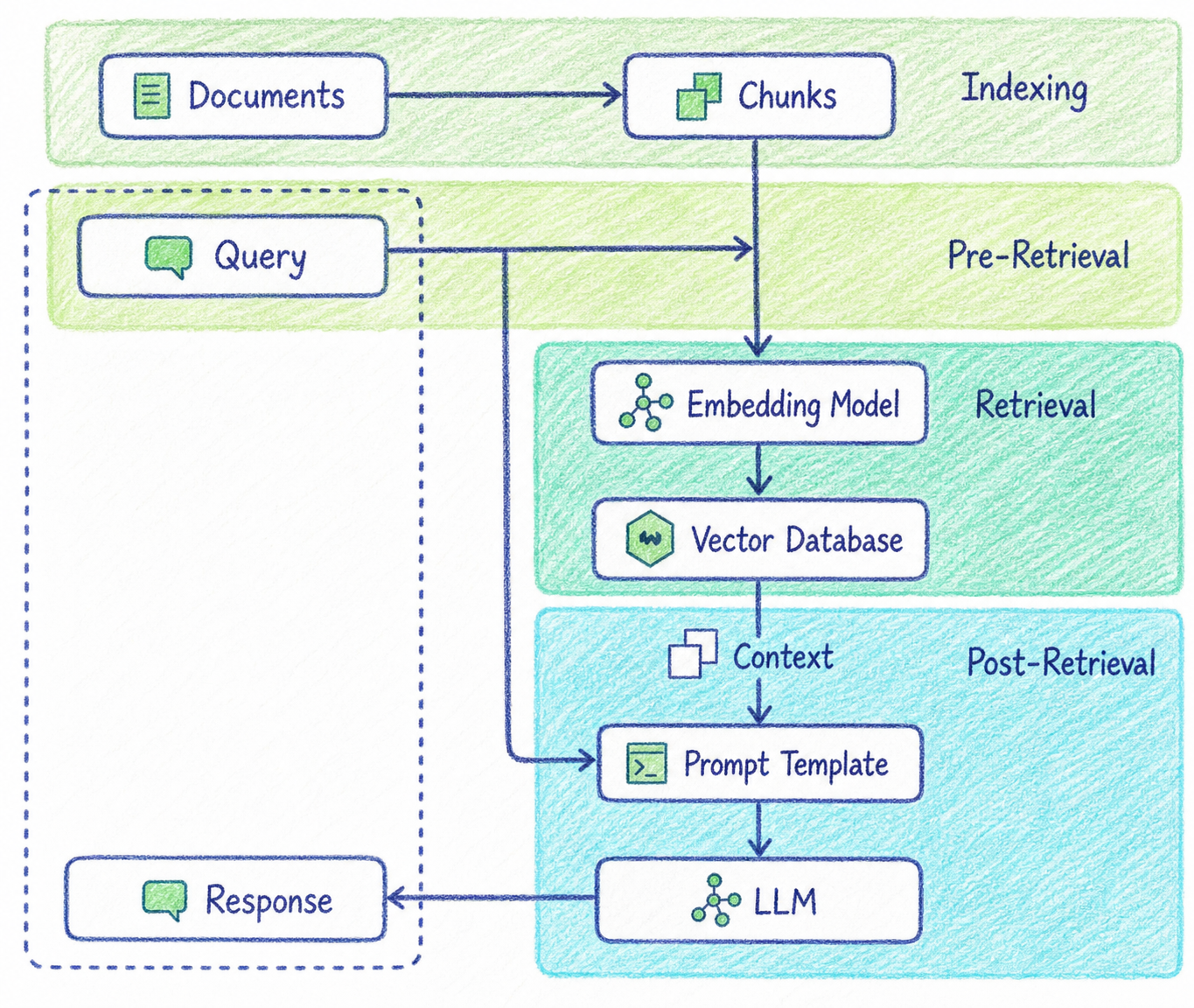
2. 데이터 전처리란?
데이터 전처리는 원본 데이터를 RAG 시스템에서 사용할 수 있는 형태로 정리하고 변환하는 과정입니다.
여기서 원본 데이터는 PDF, Word 문서, Markdown, 웹페이지, 이미지, 스프레드시트, 사내 매뉴얼, FAQ, 회의록 등 다양한 형태일 수 있습니다. 이 데이터들은 처음부터 검색에 적합한 구조로 존재하지 않는 경우가 많습니다.
예를 들어 PDF에는 페이지 번호와 footer가 반복될 수 있고, 웹페이지에는 메뉴나 광고 문구가 포함될 수 있습니다. 스캔 문서는 OCR이 필요할 수 있으며, 스프레드시트는 셀 간 관계를 함께 이해해야 합니다.
따라서 Data Pre-Processing의 핵심은 단순히 데이터를 "깨끗하게 정리하는 것"이 아닙니다. 더 정확히는 원본 데이터를 검색 가능한 지식 단위로 재구성하는 것입니다.
3. 데이터 전처리가 중요한 이유
RAG는 보통 다음과 같은 흐름으로 동작합니다.
문서 수집
↓
데이터 전처리
↓
Chunk 생성
↓
Embedding 생성
↓
Vector Database 저장
↓
사용자 질문 입력
↓
관련 Chunk 검색
↓
LLM 답변 생성
이 흐름에서 Data Pre-Processing은 앞단에 위치합니다. 앞단에서 데이터 품질이 낮으면 뒤에서 아무리 좋은 모델을 사용해도 한계가 생깁니다.
예를 들어 다음과 같은 문제가 발생할 수 있습니다.
- 불필요한 footer나 페이지 번호가 검색 결과에 포함됩니다.
- 문서가 잘못 잘려 중요한 문맥이 사라집니다.
- 제목과 본문이 분리되어 검색 결과만으로 의미를 이해하기 어렵습니다.
- 중복 문서가 많아 동일한 내용이 반복 검색됩니다.
- 출처나 작성일 같은 메타데이터가 없어 답변의 근거를 추적하기 어렵습니다.
RAG에서 검색은 LLM에게 전달할 근거를 고르는 과정입니다. 따라서 전처리가 잘못되면 LLM은 처음부터 잘못된 근거를 받게 됩니다.
4. Data Pre-Processing의 전체 흐름
Data Pre-Processing은 일반적으로 다음 단계로 구성됩니다.
원시 데이터(Raw Data)
↓
데이터 추출 및 파싱(Data Extraction & Parsing)
↓
데이터 정제(Data Cleaning)
↓
데이터 변환(Data Transformation)
↓
청크 분할(Chunking)
↓
인덱싱된 지식 베이스(Indexed Knowledge Base)
각 단계는 독립적인 작업처럼 보이지만 실제로는 서로 밀접하게 연결되어 있습니다. 추출이 잘못되면 정제할 데이터 자체가 부정확해지고, 정제가 부족하면 chunk 품질이 낮아집니다. Chunk 품질이 낮아지면 임베딩과 검색 결과에도 영향을 줍니다.
5. 데이터 수집과 통합(Data Acquisition & Integration)
전처리의 출발점은 데이터를 수집하고 통합하는 것입니다.
RAG 시스템에는 다양한 데이터 소스가 들어올 수 있습니다.
- 사내 문서
- 정책 문서
- 제품 매뉴얼
- FAQ
- 회의록
- 웹페이지
- 스프레드시트
- 이미지 기반 문서
이 단계에서 중요한 질문은 "무엇을 넣을 것인가?"입니다. 모든 데이터를 넣는 것이 항상 좋은 선택은 아닙니다. 오래된 문서, 중복 문서, 신뢰할 수 없는 문서가 포함되면 RAG의 답변 품질이 오히려 낮아질 수 있습니다.
따라서 데이터 수집 단계에서는 포함할 문서와 제외할 문서를 함께 판단해야 합니다. 특히 업무용 RAG라면 문서의 최신성, 신뢰도, 권한 범위, 출처를 함께 고려하는 것이 중요합니다.
6. 데이터 추출과 파싱(Data Extraction & Parsing)
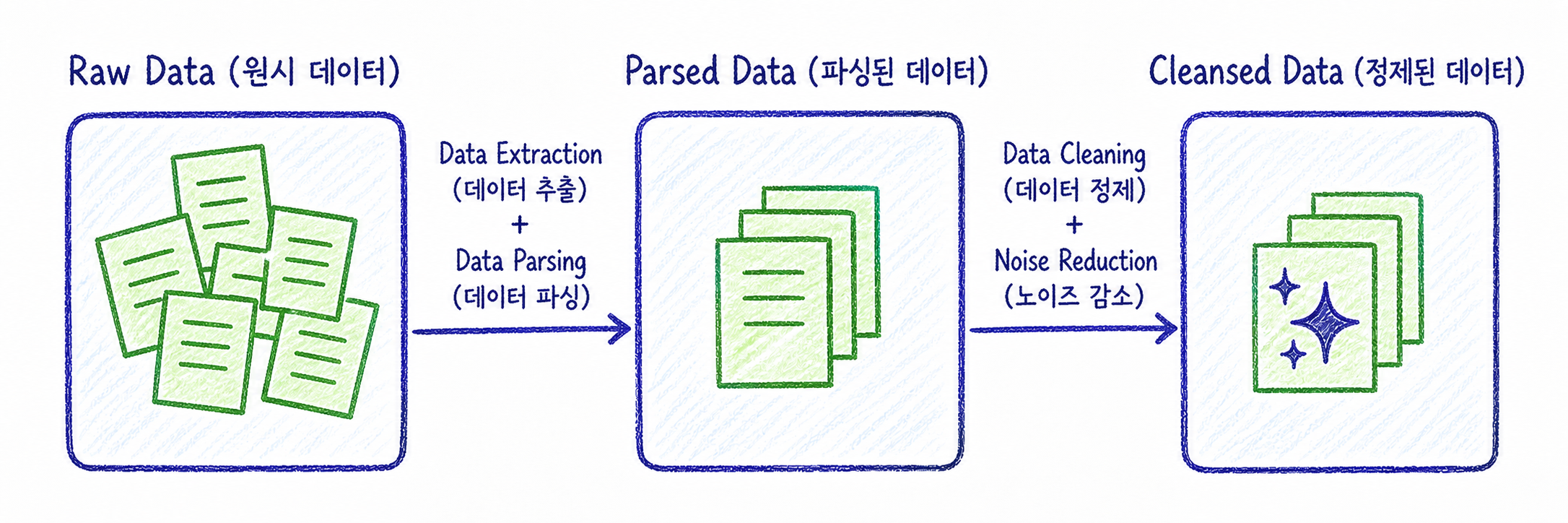
데이터를 수집했다면 다음 단계는 원본 문서에서 실제로 사용할 수 있는 내용을 추출하는 것입니다.
문서 유형에 따라 추출 방식은 달라집니다.
1. 텍스트 기반 문서
Markdown, Word, plain text 문서는 비교적 쉽게 본문을 추출할 수 있습니다. 다만 문서 안의 제목, 목록, 표, 코드 블록 같은 구조를 유지하는 것이 중요합니다.
2. PDF
PDF는 처리 난도가 높은 편입니다. 텍스트가 실제 텍스트로 포함된 PDF도 있지만, 스캔 이미지 형태로 저장된 PDF도 있습니다. 또한 여러 단, 표, 주석, footer가 섞여 있을 수 있어 단순 텍스트 추출만으로는 문맥이 깨질 수 있습니다.
3. 이미지 또는 스캔 문서
이미지 기반 문서는 OCR을 사용해 텍스트로 변환할 수 있습니다. 다만 OCR 결과에는 오탈자나 줄바꿈 오류가 포함될 수 있으므로 이후 정제 과정이 중요합니다.
4. 웹페이지
웹페이지는 HTML 파싱과 DOM 탐색을 통해 본문, 제목, 표, 링크 등을 추출합니다. 이때 메뉴, 광고, 추천 콘텐츠처럼 본문과 무관한 영역을 제거해야 합니다.
5. 스프레드시트
스프레드시트는 셀 값만 추출하면 정보가 불완전해질 수 있습니다. 행과 열의 관계, 헤더, 시트 이름, 단위, 병합 셀 등을 함께 고려해야 합니다.
6. 메타데이터도 함께 추출해야 합니다
RAG에서는 본문뿐 아니라 메타데이터도 중요합니다. 메타데이터는 검색 결과를 필터링하거나 답변의 출처를 추적하는 데 사용됩니다.
대표적인 메타데이터는 다음과 같습니다.
- 문서 제목
- 작성자
- 작성일
- 수정일
- 출처 URL 또는 파일명
- 섹션명
- 문서 유형
- 권한 또는 공개 범위
좋은 파싱은 텍스트를 많이 뽑는 것이 아니라, 의미 있는 정보와 구조를 최대한 보존하는 것입니다.
7. Data Cleaning: 검색을 방해하는 노이즈 제거
Data Cleaning은 추출된 데이터에서 불필요한 정보와 오류를 제거하는 단계입니다.
검색 품질을 낮추는 대표적인 노이즈는 다음과 같습니다.
- 반복되는 header와 footer
- 페이지 번호
- 광고 문구
- 메뉴와 내비게이션 텍스트
- 저작권 문구
- 깨진 문자
- 불필요한 공백
- 중복 문단
- 잘못 추출된 표 내용
- 누락값 또는 비정상 값
예를 들어 다음과 같은 텍스트가 있다고 가정해 보겠습니다.
NAVER WEBTOON | KOREA TEAM | Page 30
PV를 향상하기 위해서 A과제를 수행...
Copyright 2026. All rights reserved.
RAG 관점에서 실제로 필요한 내용은 가운데 문장입니다.
PV를 향상하기 위해서 A과제를 수행...
만약 header, footer, 페이지 번호가 그대로 남아 있다면 임베딩에도 영향을 주고, 검색 결과에도 불필요한 문구가 포함될 수 있습니다.
다만 Cleaning에서 주의할 점이 있습니다. 무조건 많이 지우는 것이 좋은 정제는 아닙니다. 데이터의 구조와 의미는 유지하면서 검색 품질을 떨어뜨리는 요소만 제거해야 합니다.
8. 일관된 구조로 변환(Data Transformation)
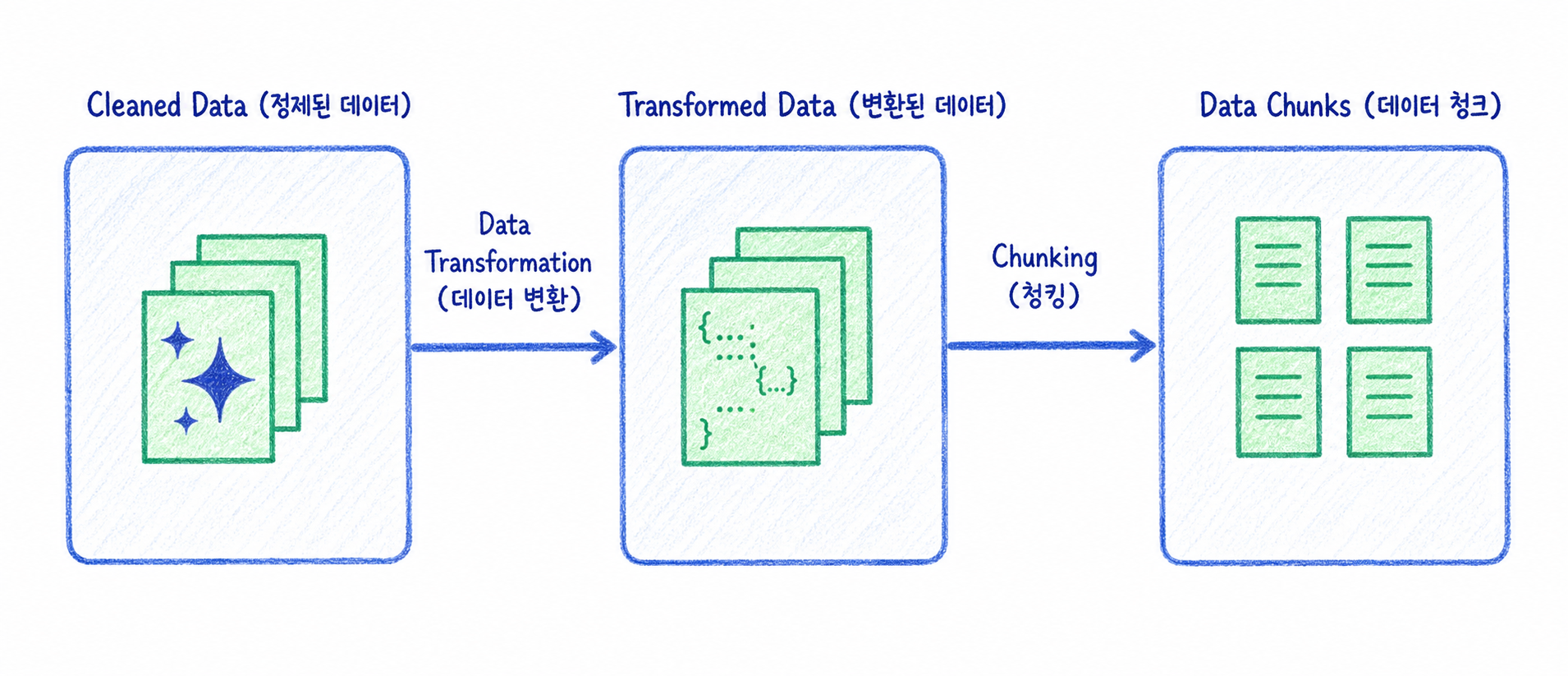
Data Transformation은 정제된 데이터를 일관된 schema나 구조로 바꾸는 단계입니다.
문서마다 형식이 다르면 검색, 필터링, 추적이 어려워집니다. 따라서 공통 schema를 정의하고 문서를 일정한 형태로 변환하는 것이 좋습니다.
예를 들어 다음과 같은 형태로 문서를 구조화할 수 있습니다.
{
"title": "문서 제목",
"section": "섹션명",
"content": "본문 내용",
"source": "파일명 또는 URL",
"created_at": "작성일",
"author": "작성자",
"document_type": "PDF"
}
이 단계에서 중요한 것은 문서를 단순한 긴 문자열로 보지 않는 것입니다. 제목, 섹션, 표, 문단, 코드 블록, 메타데이터를 가능한 한 논리적인 단위로 정리해야 합니다.
Data Transformation은 이후 검색 품질에도 큰 영향을 줍니다. 예를 들어 source, section, created_at 같은 필드를 잘 저장해두면 "최신 정책 문서만 검색"하거나 "특정 제품 문서에서만 검색"하는 방식의 필터링이 가능해집니다.
Data Transformation과 뒤에 나올 Chunking은 비슷해 보일 수 있지만 역할이 다릅니다.
Data Transformation은 문서의 논리 구조를 정리하는 단계입니다. 반면 Chunking은 검색을 위해 문서를 적절한 크기의 조각으로 나누는 단계입니다.
즉, Transformation은 문서를 어떤 구조로 표현할 것인가?에 가깝고, Chunking은 검색 단위로 어떻게 나눌 것인가?에 가깝습니다.
참고 자료
- RAG Play — 인터랙티브 RAG 파이프라인 시각화 도구
- Weaviate — Chunking Strategies for RAG
정리
RAG에서 데이터 전처리는 부가 작업이 아니라 검색 품질을 결정하는 기반 작업입니다.
문서를 그대로 벡터 DB에 넣는 것만으로는 좋은 답변을 기대하기 어렵습니다. 원본 문서를 읽을 수 있는 형태로 파싱하고, 불필요한 노이즈를 제거하고, 검색과 추적에 필요한 구조와 메타데이터를 함께 정리해야 합니다.
특히 실무에서는 전처리 품질이 낮을수록 이후 단계에서 더 많은 비용을 치르게 됩니다. chunking, embedding, retrieval을 아무리 개선해도 원본 데이터가 깨져 있거나 의미 단위가 흐트러져 있다면 검색 결과는 안정적이기 어렵습니다.
좋은 RAG를 만들고 싶다면 모델이나 벡터 DB 선택 전에 먼저 데이터가 검색 가능한 지식 단위로 준비되어 있는지 확인해야 합니다.
'AI' 카테고리의 다른 글
| 지구상에서 가장 친절한 RAG 03: 검색 전에 질문을 최적화하는 방법 (0) | 2026.06.03 |
|---|---|
| 지구상에서 가장 친절한 RAG 02: 청킹 전략은 왜 중요한가 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 00: LLM에게 필요한 정보를 찾아주는 기술 (0) | 2026.06.03 |
| 클로드코드 스킬 실전 가이드: 에이전트에게 일하는 법 가르치기 (0) | 2026.05.30 |
| 싱글 에이전트, 멀티 에이전트 어느것을 선택해야할까? (0) | 2026.05.30 |