
시작하며
RAG 시스템을 개선한다고 하면 보통 검색 알고리즘, 벡터 데이터베이스, 임베딩 모델, re-ranking 같은 요소를 먼저 떠올립니다. 하지만 검색 품질은 실제 검색이 시작되기 전부터 이미 많은 부분이 결정됩니다.
사용자의 질문이 모호하거나 너무 복잡하거나, 검색 시스템이 이해하기 어려운 형태라면 아무리 좋은 검색기를 사용해도 원하는 정보를 정확히 찾기 어렵습니다. 이 문제를 해결하기 위한 접근이 Pre-retrieval Optimization입니다.
Pre-retrieval Optimization은 검색을 수행하기 전에 사용자의 query를 더 검색하기 좋은 형태로 바꾸거나, 여러 하위 질문으로 나누거나, 적절한 검색 경로로 보내는 기법입니다. 쉽게 말하면 "검색을 잘하기 위해 질문을 먼저 정리하는 과정"입니다.
전체 흐름
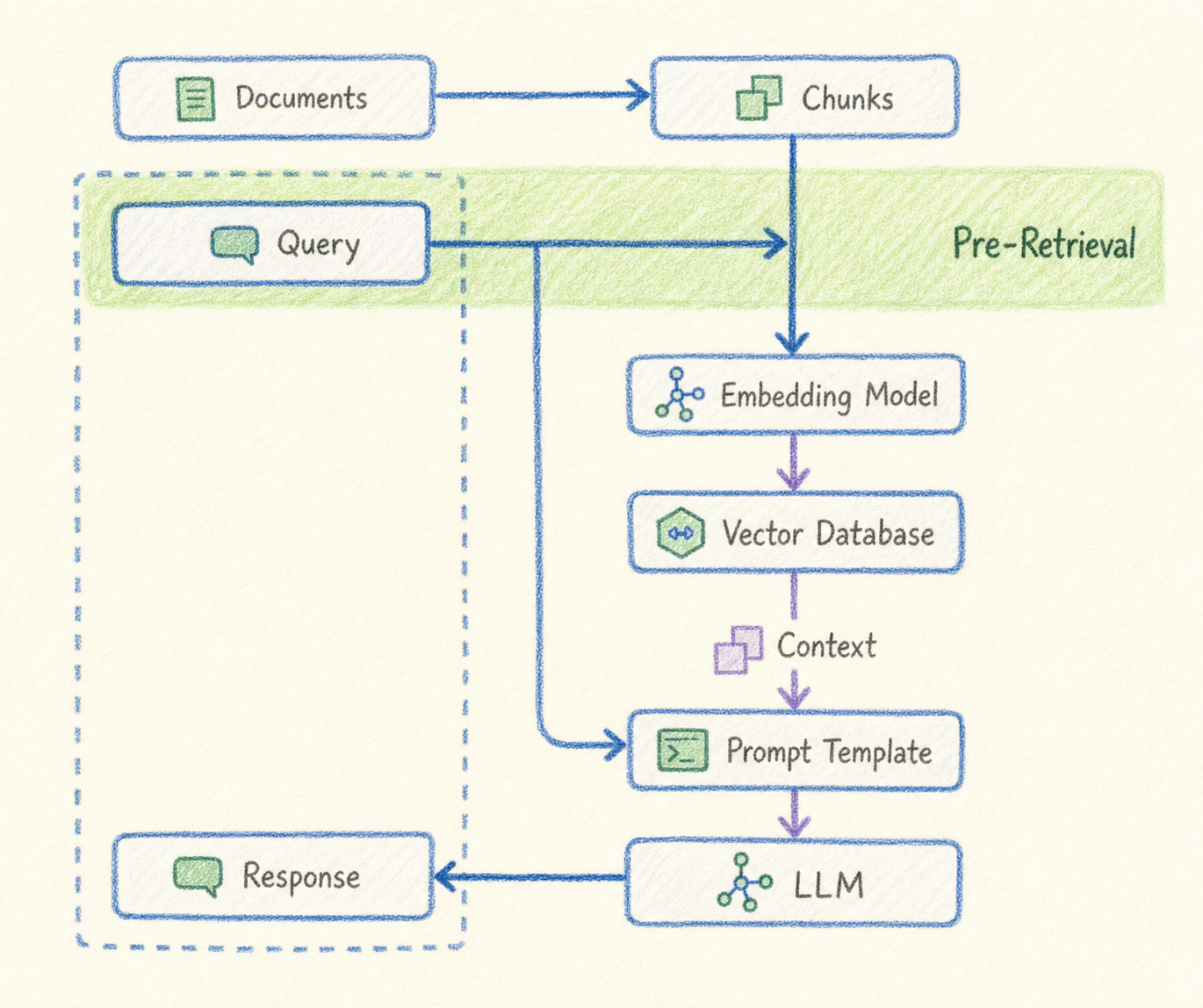
Pre-retrieval Optimization이란 무엇인가요?
Pre-retrieval Optimization은 RAG 파이프라인에서 retrieval이 실행되기 전에 적용되는 최적화 기법입니다.
일반적인 RAG 흐름은 다음과 같습니다.
사용자 질문
↓
검색
↓
관련 문서 또는 chunk 반환
↓
LLM 답변 생성여기에 Pre-retrieval Optimization을 추가하면 다음과 같은 흐름이 됩니다.
사용자 질문
↓
Query 최적화
↓
검색
↓
관련 문서 또는 chunk 반환
↓
LLM 답변 생성즉, 사용자의 원래 질문을 그대로 검색에 사용하지 않고, 검색 성능을 높이기 위해 질문을 먼저 가공합니다.
왜 검색 전에 query를 최적화해야 하나요?
사용자의 질문은 항상 검색 시스템에 친절한 형태로 들어오지 않습니다.
예를 들어 사용자는 다음과 같이 질문할 수 있습니다.
그거 지난번에 얘기한 설정 어떻게 바꾸는 거야?
사람은 대화 맥락을 통해 "그거"와 "지난번에 얘기한 설정"이 무엇인지 추론할 수 있습니다. 하지만 검색 시스템은 이 질문만 보고 정확한 문서를 찾기 어렵습니다.
또 다른 예시는 다음과 같습니다.
우리 서비스에서 관리자 권한 설정하고 SSO 연동하고 로그인 오류 해결하는 방법 알려줘.
이 질문은 하나의 질문처럼 보이지만 실제로는 여러 개의 하위 질문을 포함합니다. 관리자 권한 설정, SSO 연동, 로그인 오류 해결은 서로 다른 문서나 섹션에 존재할 가능성이 높습니다.
이처럼 query가 모호하거나 복합적이면 검색 결과의 품질이 낮아질 수 있습니다. Pre-retrieval Optimization은 이런 문제를 검색 전에 해결하려는 전략입니다.
Pre-retrieval Optimization의 핵심 아이디어
Pre-retrieval Optimization의 핵심은 세 가지로 정리할 수 있습니다.
- 질문을 검색하기 좋은 형태로 바꿉니다.
- 복잡한 질문을 더 작은 질문으로 나눕니다.
- 질문의 의도에 맞는 검색 경로로 보냅니다.
이 세 가지는 각각 다음 기법으로 연결됩니다.
- Query Transformation
- Query Decomposition
- Query Routing
이제 각 기법을 하나씩 살펴보겠습니다.
1. Query Transformation: 질문을 검색하기 좋은 형태로 바꾸기
Query Transformation은 사용자의 원본 query를 검색에 더 적합한 형태로 변환하는 기법입니다.
사용자의 질문은 짧거나 모호하거나, 문서에 사용된 표현과 다를 수 있습니다. Query Transformation은 이런 query를 더 명확하고 풍부한 검색 query로 바꿉니다.
대표적인 방식은 Query Rewriting과 Query Expansion입니다.
Query Rewriting
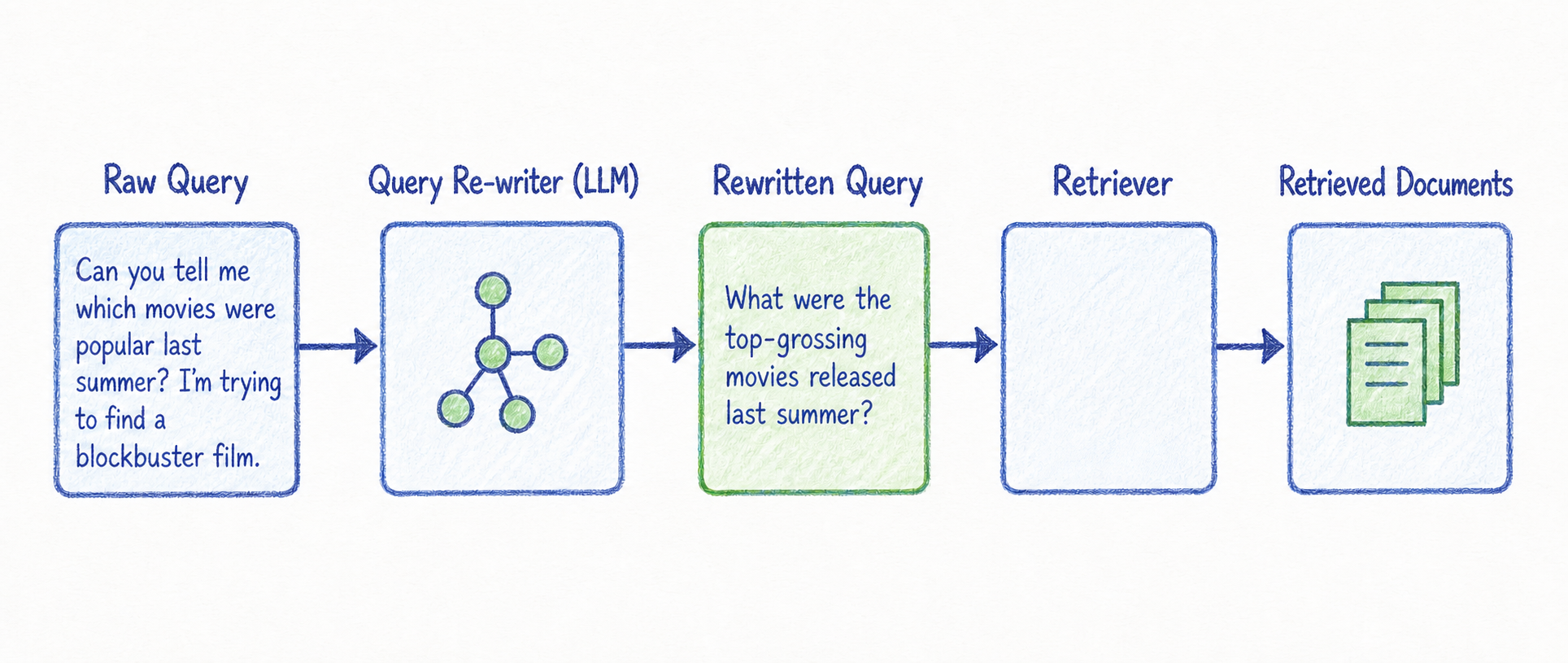
Query Rewriting은 사용자의 질문을 더 명확한 표현으로 다시 쓰는 방식입니다.
예를 들어 사용자가 다음과 같이 질문했다고 가정해보겠습니다.
비밀번호 안 돼요.
이 질문은 너무 짧고 모호합니다. 검색 시스템은 "비밀번호가 틀린 것인지", "비밀번호 재설정이 안 되는 것인지", "로그인이 안 되는 것인지"를 알기 어렵습니다.
Query Rewriting을 적용하면 다음과 같이 바꿀 수 있습니다.
비밀번호 오류로 로그인할 수 없을 때 해결 방법
또는 대화 맥락이 있다면 다음처럼 더 구체화할 수 있습니다.
관리자 계정에서 비밀번호 오류가 발생해 로그인할 수 없을 때 해결 방법
이렇게 query를 다시 쓰면 검색 대상 문서와 더 잘 매칭될 가능성이 높아집니다.
Query Rewriting이 유용한 경우
- 질문이 너무 짧을 때
- 지시어가 포함되어 있을 때
- 대화 맥락이 필요한 질문일 때
- 사용자의 표현과 문서의 표현이 다를 때
- 오타나 비표준 표현이 포함되어 있을 때
Query Expansion
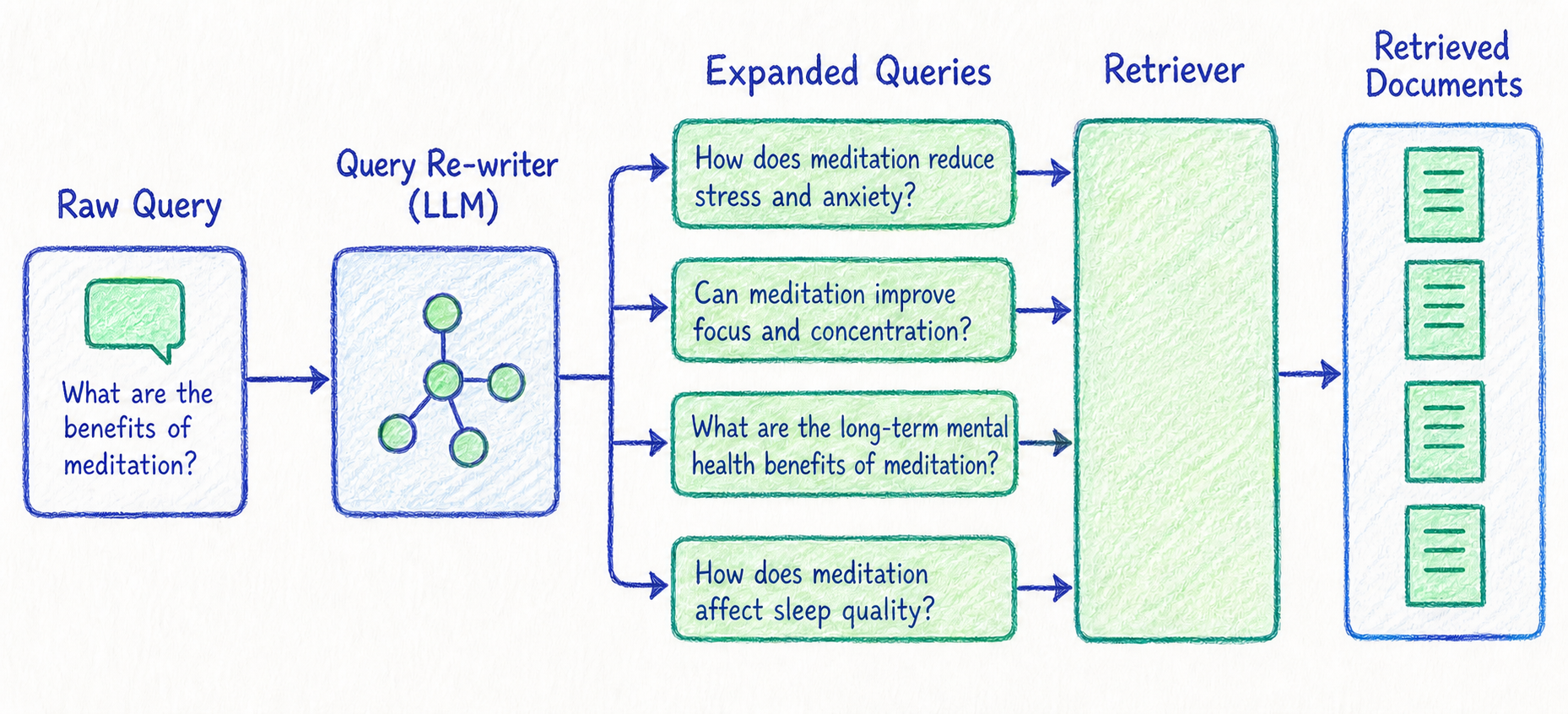
Query Expansion은 원래 질문에 관련 키워드나 동의어, 상위 개념, 하위 개념을 추가해 검색 범위를 넓히는 방식입니다.
예를 들어 사용자가 다음과 같이 질문했다고 가정해보겠습니다.
SSO 설정 방법 알려줘.
문서에서는 SSO라는 표현 대신 "Single Sign-On", "통합 로그인", "SAML", "OIDC" 같은 표현을 사용할 수 있습니다. Query Expansion은 이런 관련 표현을 query에 추가합니다.
SSO 설정 방법, Single Sign-On 구성, 통합 로그인, SAML, OIDC 연동
이렇게 하면 사용자의 표현과 문서의 표현이 정확히 일치하지 않아도 관련 문서를 찾을 가능성이 높아집니다.
Query Expansion이 유용한 경우
- 문서마다 용어가 다르게 쓰일 때
- 약어와 풀네임이 섞여 있을 때
- 사용자 표현과 공식 문서 표현이 다를 때
- 검색 recall을 높이고 싶을 때
다만 expansion을 과하게 하면 관련 없는 문서까지 검색될 수 있습니다. 따라서 검색 범위를 넓히되, query의 원래 의도에서 벗어나지 않도록 조절해야 합니다.
Query Transformation의 장점과 주의점
Query Transformation의 장점은 사용자의 질문을 검색 시스템이 더 잘 이해할 수 있는 형태로 바꾼다는 점입니다. 특히 실제 서비스에서는 사용자가 항상 정확한 용어를 쓰지 않기 때문에 매우 유용합니다.
하지만 주의할 점도 있습니다. query를 너무 많이 바꾸면 사용자의 의도가 왜곡될 수 있습니다. 예를 들어 "로그인 오류"를 "계정 잠금 해제"로 지나치게 구체화하면, 실제 사용자가 원한 답과 다른 문서가 검색될 수 있습니다.
따라서 Query Transformation은 원래 질문의 의미를 보존하면서 검색 가능성을 높이는 방향으로 설계해야 합니다.
2. Query Decomposition: 복잡한 질문을 하위 질문으로 나누기
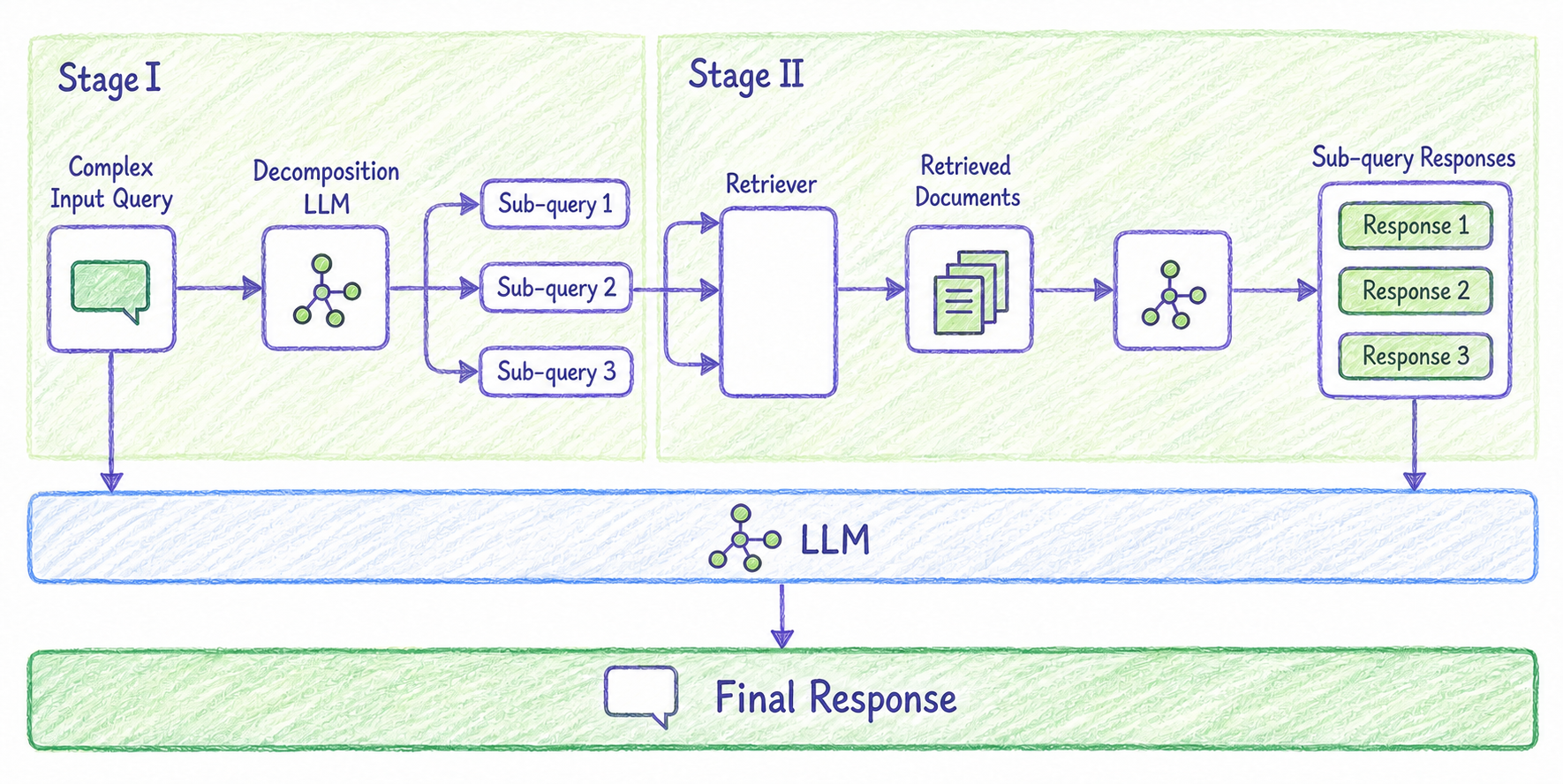
Query Decomposition은 복잡한 query를 여러 개의 더 단순한 query로 나누는 기법입니다.
사용자의 질문에는 여러 의도가 한꺼번에 들어 있을 수 있습니다. 이때 하나의 query로 검색하면 각 의도에 필요한 문서를 충분히 찾지 못할 수 있습니다.
예를 들어 다음 질문을 보겠습니다.
관리자 계정을 만들고 권한을 설정한 다음 SSO까지 연동하는 방법을 알려줘.
이 질문은 실제로 세 개의 하위 질문으로 나눌 수 있습니다.
- 관리자 계정을 만드는 방법은 무엇인가요?
- 관리자 계정의 권한을 설정하는 방법은 무엇인가요?
- SSO를 연동하는 방법은 무엇인가요?
각 하위 질문은 서로 다른 문서를 검색할 수 있습니다. 이후 검색 결과를 합쳐 LLM에게 전달하면 더 포괄적이고 정확한 답변을 만들 수 있습니다.
Query Decomposition이 필요한 이유
복잡한 질문을 하나의 query로 검색하면 검색 결과가 한쪽 주제에 치우칠 수 있습니다.
예를 들어 위 질문을 그대로 검색하면 "SSO 연동" 문서만 많이 검색되고, "관리자 계정 생성"이나 "권한 설정" 문서는 누락될 수 있습니다.
Query Decomposition은 이런 문제를 줄여줍니다. 질문을 하위 문제로 나누고 각각 검색하기 때문에, 복합 질문에 필요한 정보를 더 균형 있게 수집할 수 있습니다.
Query Decomposition이 유용한 경우
Query Decomposition은 다음과 같은 질문에 특히 유용합니다.
- 여러 단계의 절차를 묻는 질문
- 여러 개념을 비교하는 질문
- 원인과 해결책을 함께 묻는 질문
- 여러 조건을 포함하는 질문
- 긴 설명형 답변이 필요한 질문
예를 들어 다음 질문들은 decomposition 대상이 될 수 있습니다.
- A 기능과 B 기능의 차이점과 각각의 설정 방법을 알려줘.
- 결제 실패 원인과 사용자에게 안내해야 할 해결 방법을 정리해줘.
- 신규 입사자가 계정을 만들고 VPN에 접속하고 메일을 설정하는 전체 절차를 알려줘.
이런 질문은 하나의 검색으로 처리하기보다 하위 질문으로 나누는 편이 더 안정적입니다.
Query Decomposition의 주의점
Query Decomposition은 복잡한 질문에 강력하지만, 모든 질문에 적용할 필요는 없습니다.
단순한 질문을 억지로 나누면 오히려 검색 비용이 증가하고, 불필요한 결과가 많아질 수 있습니다.
예를 들어 다음 질문은 decomposition이 필요하지 않습니다.
비밀번호 재설정 링크는 어디에 있나요?
이 질문은 하나의 검색으로도 충분히 처리할 수 있습니다.
따라서 query의 복잡도를 먼저 판단하고, 여러 하위 의도가 있을 때만 decomposition을 적용하는 것이 좋습니다.
3. Query Routing: 질문을 적절한 검색 경로로 보내기
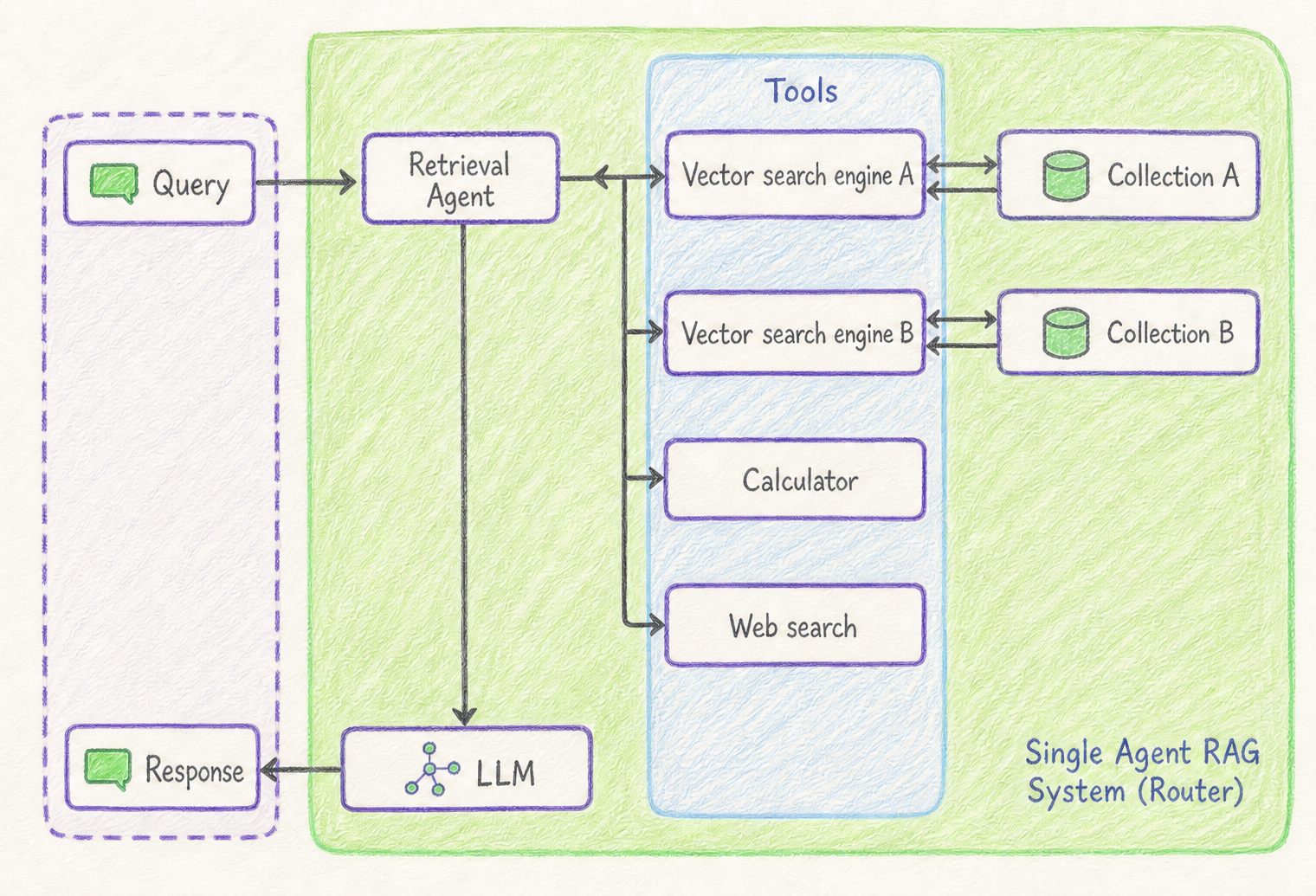
Query Routing은 query의 내용과 의도에 따라 적절한 검색 경로 또는 처리 파이프라인으로 보내는 기법입니다.
RAG 시스템이 하나의 지식베이스만 사용하는 경우에는 routing이 단순할 수 있습니다. 하지만 실제 서비스에서는 여러 데이터 소스, 여러 인덱스, 여러 검색 방식이 함께 존재하는 경우가 많습니다.
예를 들어 사내 RAG 시스템에는 다음과 같은 데이터 소스가 있을 수 있습니다.
- 제품 매뉴얼
- 장애 대응 문서
- 보안 정책 문서
- 인사 규정
- API 문서
- 고객 FAQ
사용자의 질문이 "휴가 신청 방법"이라면 인사 규정이나 사내 포털 문서를 검색해야 합니다. 반면 "API 인증 토큰 갱신 방법"이라면 API 문서를 검색해야 합니다.
Query Routing은 이런 판단을 검색 전에 수행합니다.
Query Routing이 유용한 경우
Query Routing은 다음 상황에서 특히 유용합니다.
- 여러 개의 지식베이스가 존재할 때
- 도메인별 인덱스가 분리되어 있을 때
- 질문 유형에 따라 검색 방식이 달라야 할 때
- 일부 질문은 vector search, 일부 질문은 keyword search가 더 적합할 때
- 민감한 문서 접근 권한을 분리해야 할 때
예를 들어 기술 문서는 vector search를 사용하고, 특정 에러 코드 검색은 keyword search를 사용하는 방식이 가능합니다. 또는 사용자의 권한에 따라 검색 가능한 문서 범위를 다르게 설정할 수도 있습니다.
Query Routing의 주의점
Routing이 잘못되면 적절한 문서를 아예 검색하지 못할 수 있습니다. 예를 들어 보안 정책 문서로 가야 할 질문이 제품 FAQ로 routing되면, 아무리 검색을 잘해도 필요한 정보가 나오지 않습니다.
따라서 routing 기준은 명확해야 합니다. 단순 키워드 기반 routing을 사용할 수도 있고, classifier나 LLM을 활용해 의도를 분류할 수도 있습니다. 중요한 것은 routing 결과를 모니터링하고, 잘못된 routing 사례를 지속적으로 개선하는 것입니다.
Pre-retrieval Optimization 전략 비교
| 전략 | 핵심 역할 | 장점 | 주의점 | 적합한 경우 |
|---|---|---|---|---|
| Query Transformation | query를 검색하기 좋은 형태로 바꿉니다 | 모호한 질문의 검색 품질을 높입니다 | 의도 왜곡을 주의해야 합니다 | 짧거나 불명확한 질문 |
| Query Expansion | 관련 키워드와 동의어를 추가합니다 | recall을 높일 수 있습니다 | 과도하면 노이즈가 증가합니다 | 용어 차이가 큰 문서 |
| Query Decomposition | 복잡한 질문을 하위 질문으로 나눕니다 | 복합 질문을 더 정확히 처리합니다 | 불필요한 검색 비용이 늘 수 있습니다 | 다단계, 비교, 복합 질문 |
| Query Routing | 적절한 검색 경로를 선택합니다 | 관련 데이터 소스를 빠르게 찾습니다 | routing 오류가 치명적일 수 있습니다 | 여러 인덱스나 데이터 소스가 있는 경우 |
실무 설계 체크리스트
모든 RAG 시스템에 모든 pre-retrieval 기법을 적용할 필요는 없습니다. 시스템의 문제 유형에 따라 우선순위를 정하는 것이 좋습니다.
Query Transformation
예를 들어 사용자가 "이거 설정하는 방법 알려줘"라고 묻는다면, 이전 대화 맥락을 반영해 "SSO 인증 설정 방법"처럼 검색 가능한 명확한 질의로 변환할 수 있습니다. 또한 사용자의 표현을 문서에서 사용하는 공식 용어로 바꾸거나, 모호한 질문을 더 구체적인 검색 질의로 정리할 수 있습니다.
- 사용자의 질문이 검색에 충분히 명확한가요?
- 대화 맥락을 반영해야 하나요?
- 문서에서 사용하는 공식 용어로 변환할 필요가 있나요?
- query rewriting 과정에서 의도가 왜곡되지는 않나요?
Query Expansion
문서와 사용자의 용어가 다르다면 Query Expansion이 유용합니다. 예를 들어 사용자는 "통합 로그인"이라고 묻지만 문서에는 SSO, SAML, OIDC라고 쓰여 있을 수 있습니다.
- 동의어, 약어, 영문명, 한글명이 함께 존재하나요?
- expansion이 검색 recall을 높이나요?
- 너무 많은 키워드가 추가되어 노이즈가 증가하지는 않나요?
Query Decomposition
질문이 여러 의도를 포함한다면 사용하면 좋습니다. 예를 들어 "계정 생성, 권한 설정, SSO 연동 방법을 알려줘"는 세 개의 하위 질문으로 나누는 것이 더 좋습니다.
- 질문 안에 여러 하위 의도가 있나요?
- 각 하위 질문이 독립적으로 검색될 수 있나요?
- 검색 결과를 다시 합쳐 하나의 답변으로 구성할 수 있나요?
Query Routing
데이터 소스가 여러 개라면 Query Routing을 사용하는 것이 좋습니다. 예를 들어 인사 문서, 기술 문서, 고객 FAQ, 장애 대응 문서가 분리되어 있다면 질문의 의도에 맞는 데이터 소스로 보내야 합니다.
- 데이터 소스나 인덱스가 여러 개인가요?
- 질문 유형별로 적합한 검색 방식이 다른가요?
- routing 실패 사례를 모니터링할 수 있나요?
- 사용자 권한에 따라 검색 범위를 제한해야 하나요?
Pre-retrieval Optimization의 한계
Pre-retrieval Optimization은 강력하지만 만능은 아닙니다.
먼저 query를 변환하는 과정에서 사용자의 원래 의도가 바뀔 수 있습니다. 특히 LLM을 사용해 query를 rewrite하거나 decompose할 때는 원래 질문의 의미를 보존하는 것이 중요합니다.
또한 query를 여러 개로 나누거나 확장하면 검색 횟수가 늘어나 비용과 latency가 증가할 수 있습니다. 운영 환경에서는 정확도 향상과 응답 속도 사이의 균형을 고려해야 합니다.
마지막으로 routing이 잘못되면 관련 문서를 아예 찾지 못할 수 있습니다. 따라서 pre-retrieval 단계의 각 판단은 로그로 남기고, 실제 사용자 질문과 검색 결과를 기반으로 지속적으로 개선해야 합니다.
마치며
Pre-retrieval Optimization은 검색 전에 query를 더 좋은 형태로 만드는 과정입니다.
RAG 시스템에서 사용자의 질문은 항상 명확하지 않습니다. 짧거나 모호할 수 있고, 여러 의도를 포함할 수 있으며, 적절한 데이터 소스를 선택해야 할 수도 있습니다.
이때 Query Transformation, Query Decomposition, Query Routing을 적용하면 검색기가 더 좋은 후보 문서를 찾을 수 있습니다.
핵심은 다음과 같습니다.
- Query Transformation은 질문을 검색하기 좋은 형태로 바꿉니다.
- Query Expansion은 관련 표현을 추가해 검색 범위를 넓힙니다.
- Query Decomposition은 복잡한 질문을 하위 질문으로 나눕니다.
- Query Routing은 질문을 적절한 데이터 소스나 검색 경로로 보냅니다.
결국 Pre-retrieval Optimization은 검색 성능을 높이기 위한 "질문 설계"에 가깝습니다. 좋은 검색 결과는 좋은 query에서 시작되고, 좋은 query는 사용자의 질문을 정확히 이해하고 검색 시스템에 맞게 정리하는 과정에서 만들어집니다.
'AI' 카테고리의 다른 글
| 지구상에서 가장 친절한 RAG 05: 검색된 근거를 더 잘 쓰는 방법 (0) | 2026.06.03 |
|---|---|
| 지구상에서 가장 친절한 RAG 04: 더 좋은 근거를 찾는 검색 전략 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 02: 청킹 전략은 왜 중요한가 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 01: 데이터 전처리가 검색 품질을 결정하는 이유 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 00: LLM에게 필요한 정보를 찾아주는 기술 (0) | 2026.06.03 |