
시작하며
RAG 시스템의 핵심은 "필요한 정보를 얼마나 잘 찾아오느냐"에 있습니다. LLM이 아무리 뛰어나도 검색 단계에서 관련 없는 문서가 들어오면 답변 품질은 낮아집니다. 반대로 사용자의 질문과 정확히 맞는 근거 문서를 찾아오면, LLM은 더 정확하고 신뢰할 수 있는 답변을 생성할 수 있습니다.
이때 중요한 것이 Retrieval Optimization입니다.
Retrieval Optimization은 사용자의 query에 대해 더 관련성 높은 문서나 chunk를 찾아오기 위해 검색 방식을 개선하는 전략입니다. 앞서 다룬 Pre-retrieval Optimization이 "검색 전에 query를 정리하는 과정"이었다면, Retrieval Optimization은 "검색을 수행하는 방식 자체를 개선하는 과정"입니다.
전체 흐름
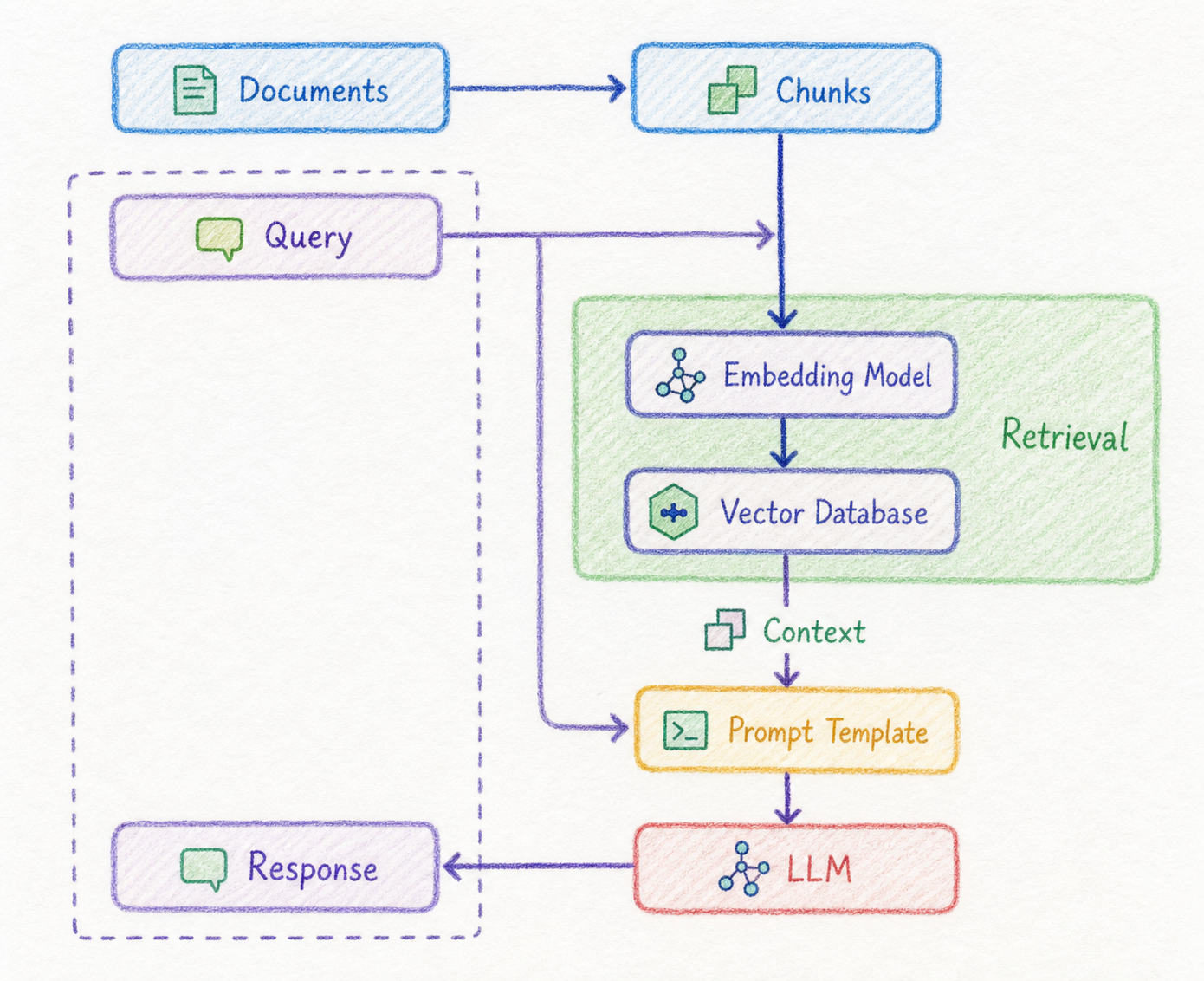
Retrieval Optimization이란 무엇인가요?
Retrieval Optimization은 RAG 파이프라인에서 실제 검색 단계의 품질을 높이는 기법입니다.
일반적인 RAG 흐름은 다음과 같습니다.
사용자 질문
↓
Query 최적화
↓
검색 Retrieval
↓
관련 문서 또는 chunk 반환
↓
LLM 답변 생성여기서 Retrieval 단계는 사용자의 질문과 관련 있는 정보를 지식베이스에서 찾아오는 역할을 합니다.
이 검색 단계가 부정확하면 LLM은 잘못된 근거를 바탕으로 답변하게 됩니다. 따라서 Retrieval Optimization의 목표는 단순히 "많이 찾아오기"가 아니라, 정확한 정보를, 적절한 순서로, 충분한 다양성을 가지고 찾아오는 것입니다.
왜 Retrieval Optimization이 중요한가요?
RAG에서 LLM은 검색 결과를 근거로 답변을 생성합니다. 따라서 검색 결과의 품질은 최종 답변 품질에 직접적인 영향을 줍니다.
검색이 잘못되면 다음과 같은 문제가 발생할 수 있습니다.
- 질문과 관련 없는 chunk가 검색됩니다.
- 중요한 문서가 검색 결과에서 누락됩니다.
- 비슷한 내용의 chunk만 반복해서 검색됩니다.
- 오래되거나 신뢰도가 낮은 문서가 상위에 노출됩니다.
- 키워드는 맞지만 의미가 다른 문서가 선택됩니다.
이 문제들은 LLM 단계에서 완전히 해결하기 어렵습니다. LLM은 주어진 context 안에서 답변을 생성하기 때문에, 애초에 잘못된 context가 들어오면 답변도 흔들릴 수밖에 없습니다.
Retrieval Optimization의 핵심 방향
Retrieval Optimization은 크게 네 가지 방향으로 이해할 수 있습니다.
- 의미 기반 검색을 잘 활용합니다.
- 키워드 기반 검색의 장점을 함께 사용합니다.
- 메타데이터를 활용해 검색 범위를 좁힙니다.
- 검색 결과의 다양성과 관련성을 함께 조절합니다.
이 방향은 각각 다음과 같은 전략으로 연결됩니다.
- Vector Search
- Keyword Search
- Hybrid Search
- Metadata Filtering
- Auto-cut 또는 Similarity Threshold
- Multi-vector Retrieval
이제 각 전략을 하나씩 살펴보겠습니다.
1. Vector Search: 의미적으로 가까운 문서를 찾기
Vector Search는 RAG에서 가장 널리 사용되는 검색 방식입니다. 문서 chunk와 사용자 질문을 embedding으로 변환한 뒤, 벡터 공간에서 가까운 chunk를 찾습니다.
예를 들어 사용자가 다음과 같이 질문했다고 가정해보겠습니다.
비밀번호를 잊어버렸을 때 어떻게 해야 하나요?문서에는 다음과 같이 표현되어 있을 수 있습니다.
계정 암호를 분실한 경우 재설정 링크를 통해 새 암호를 설정할 수 있습니다.
두 문장은 사용한 단어가 다르지만 의미는 비슷합니다. Vector Search는 이런 의미적 유사성을 바탕으로 관련 문서를 찾을 수 있습니다.
장점
Vector Search의 가장 큰 장점은 표현이 정확히 일치하지 않아도 의미가 비슷한 문서를 찾을 수 있다는 점입니다. 사용자가 문서에 있는 공식 용어를 모르더라도 관련 정보를 찾을 가능성이 높아집니다.
단점
Vector Search는 의미 기반 검색에 강하지만, 특정 키워드나 코드, 고유명사, 버전명, 에러 코드처럼 정확한 문자열 일치가 중요한 경우에는 약할 수 있습니다.
예를 들어 ERR_AUTH_401 같은 에러 코드를 검색할 때는 의미적 유사성보다 정확한 키워드 매칭이 더 중요합니다.
2. Keyword Search: 정확한 단어 일치가 중요한 검색
Keyword Search는 사용자의 query에 포함된 단어와 문서에 포함된 단어가 얼마나 잘 일치하는지를 기준으로 검색합니다.
전통적인 검색 엔진에서 많이 사용되는 방식이며, BM25 같은 알고리즘이 대표적입니다.
장점
Keyword Search는 특정 용어, 제품명, API 이름, 에러 코드, 법률 조항, 버전명처럼 정확한 단어가 중요한 검색에 강합니다.
예를 들어 사용자가 다음과 같이 질문한다고 가정해보겠습니다.
ERR_AUTH_401 오류 해결 방법 알려줘.이 경우 의미적으로 비슷한 문서를 찾는 것보다 ERR_AUTH_401이라는 정확한 문자열이 포함된 문서를 찾는 것이 중요합니다.
단점
Keyword Search는 사용자의 표현과 문서의 표현이 다르면 관련 문서를 놓칠 수 있습니다. 사용자가 "비밀번호"라고 질문했는데 문서에는 "암호"라고 쓰여 있다면 검색 성능이 떨어질 수 있습니다.
3. Hybrid Search: Vector Search와 Keyword Search를 함께 사용하기
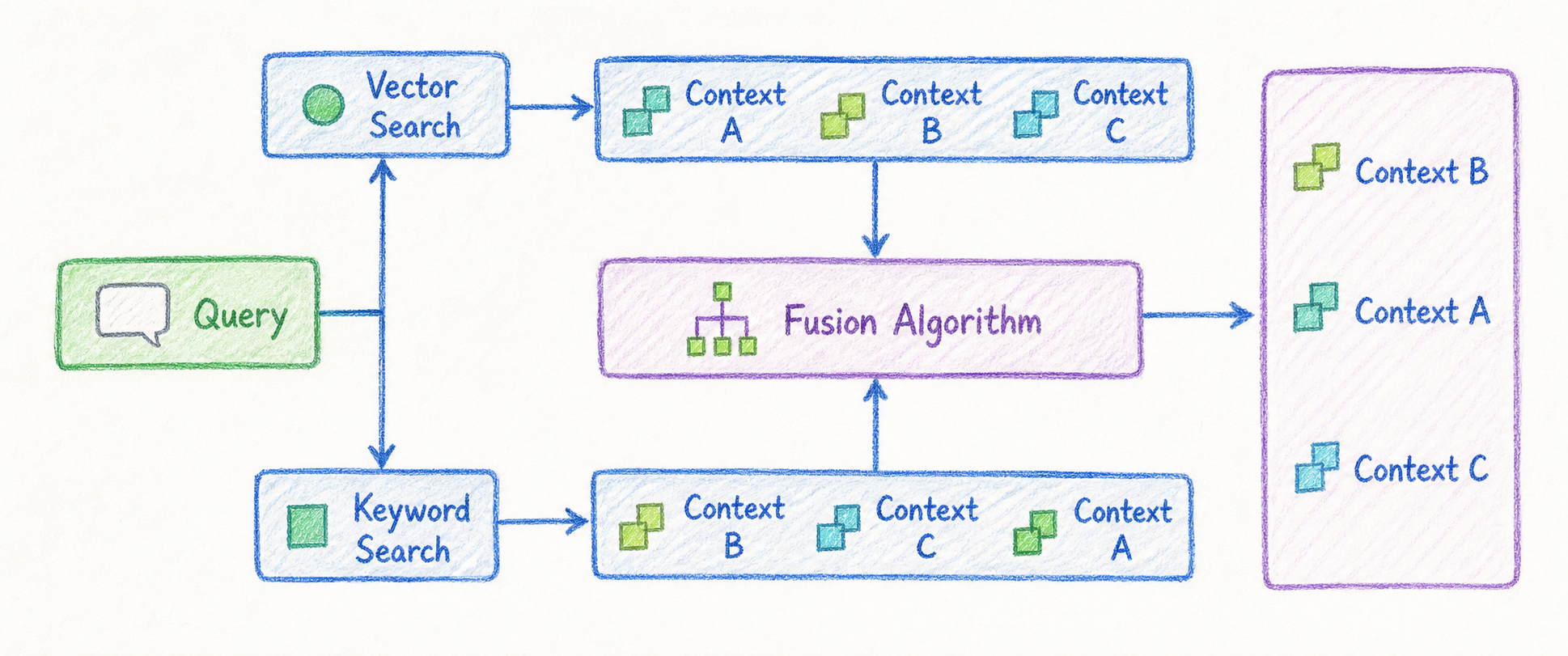
Hybrid Search는 Vector Search와 Keyword Search를 결합하는 방식입니다.
Vector Search는 의미적 유사성에 강하고, Keyword Search는 정확한 단어 일치에 강합니다. Hybrid Search는 두 방식의 장점을 함께 활용해 검색 품질을 높입니다.
예를 들어 사용자가 다음과 같이 질문했다고 가정해보겠습니다.
SSO 설정 중 SAML 인증 오류가 발생했을 때 해결 방법 알려줘.이 질문에는 의미 기반 검색이 필요한 부분도 있고, SSO, SAML처럼 정확히 매칭되어야 하는 키워드도 있습니다. Hybrid Search는 이런 질문에 특히 유용합니다.
Hybrid Search의 장점
Hybrid Search는 다음과 같은 상황에서 강점을 가집니다.
- 사용자의 질문에 일반 표현과 전문 용어가 섞여 있을 때
- 의미적으로 유사한 문서도 찾고 싶지만 특정 키워드도 놓치면 안 될 때
- 에러 코드, 제품명, 기능명, 약어가 중요한 문서 검색
- 키워드 검색만으로는 recall이 낮고, 벡터 검색만으로는 precision이 낮을 때
주의할 점
Hybrid Search에서는 vector score와 keyword score를 어떻게 결합할지가 중요합니다. 한쪽 점수에 너무 많은 비중을 두면 다른 방식의 장점이 줄어들 수 있습니다.
따라서 도메인에 따라 가중치를 조정하고, 실제 사용자 질문을 기준으로 검색 결과를 평가해야 합니다.
4. Metadata Filtering: 검색 범위를 더 정확하게 좁히기
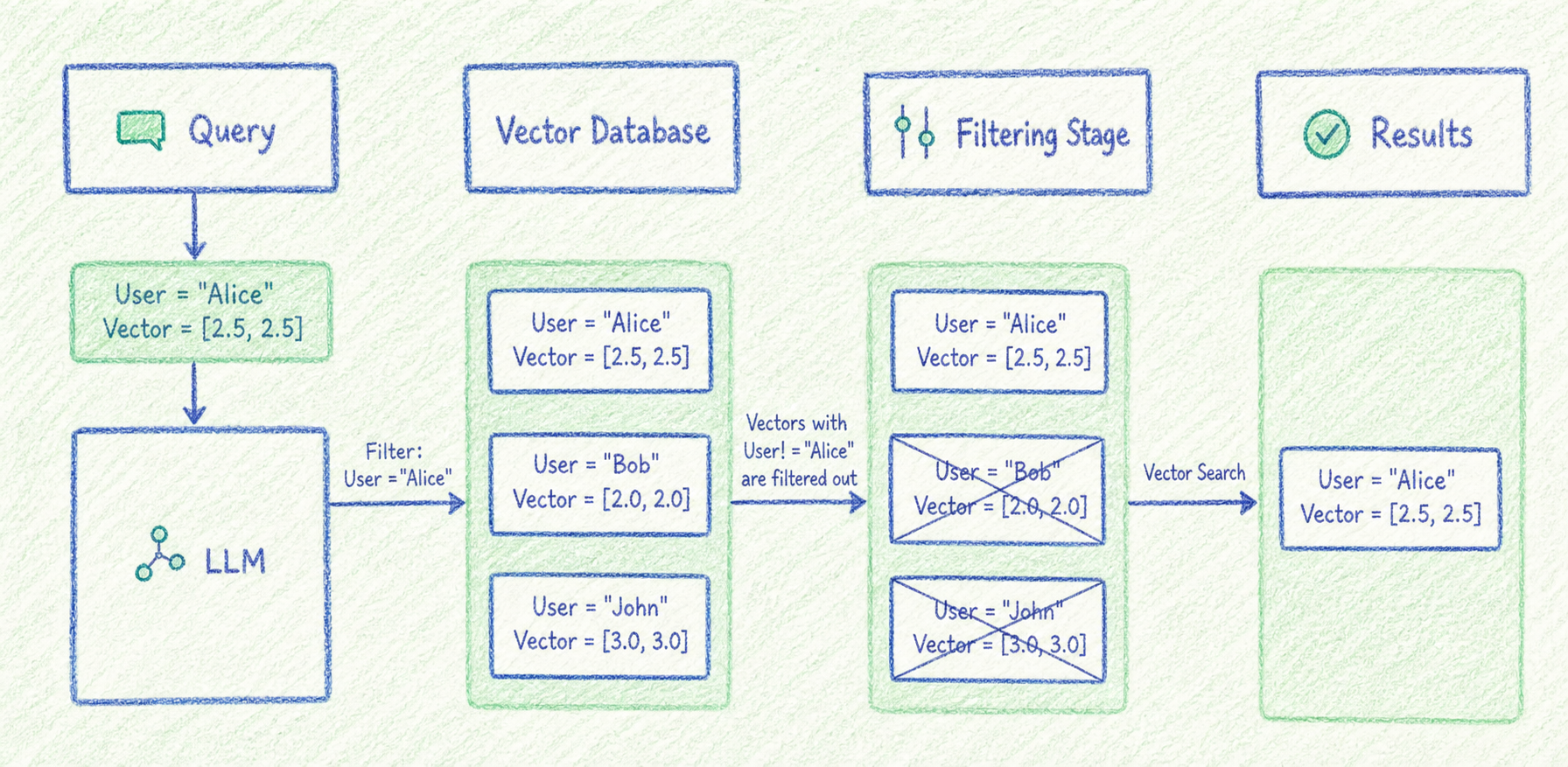
Metadata Filtering은 문서의 본문뿐 아니라 메타데이터를 활용해 검색 범위를 제한하는 전략입니다.
문서 chunk에는 보통 다음과 같은 메타데이터를 함께 저장할 수 있습니다.
- 문서 제목
- 문서 유형
- 작성일
- 수정일
- 작성자
- 제품명
- 버전
- 권한 범위
- 부서
- 언어
- source URL
이 메타데이터를 검색 조건으로 활용하면 더 정확한 검색이 가능합니다.
예시
사용자가 다음과 같이 질문한다고 가정해보겠습니다.
최신 버전에서 관리자 권한 설정 방법 알려줘.이때 단순히 관리자 권한 설정"만 검색하면 오래된 문서가 함께 검색될 수 있습니다. 하지만 metadata filtering을 적용하면 최신 버전 문서만 검색하도록 제한할 수 있습니다.
product = "Admin Console"
version = "latest"
document_type = "manual"장점
Metadata Filtering은 검색 결과의 정확도를 높이고, 불필요한 문서를 줄이는 데 효과적입니다. 특히 기업 내부 RAG처럼 문서가 많고 권한이나 최신성이 중요한 환경에서 매우 유용합니다.
주의할 점
메타데이터 품질이 낮으면 filtering도 제대로 동작하지 않습니다. 따라서 metadata filtering은 앞단의 Data Pre-Processing과 강하게 연결됩니다. 문서 수집과 변환 단계에서 메타데이터를 일관되게 저장해야 합니다.
5. Similarity Threshold: 관련성이 낮은 결과를 제외하기
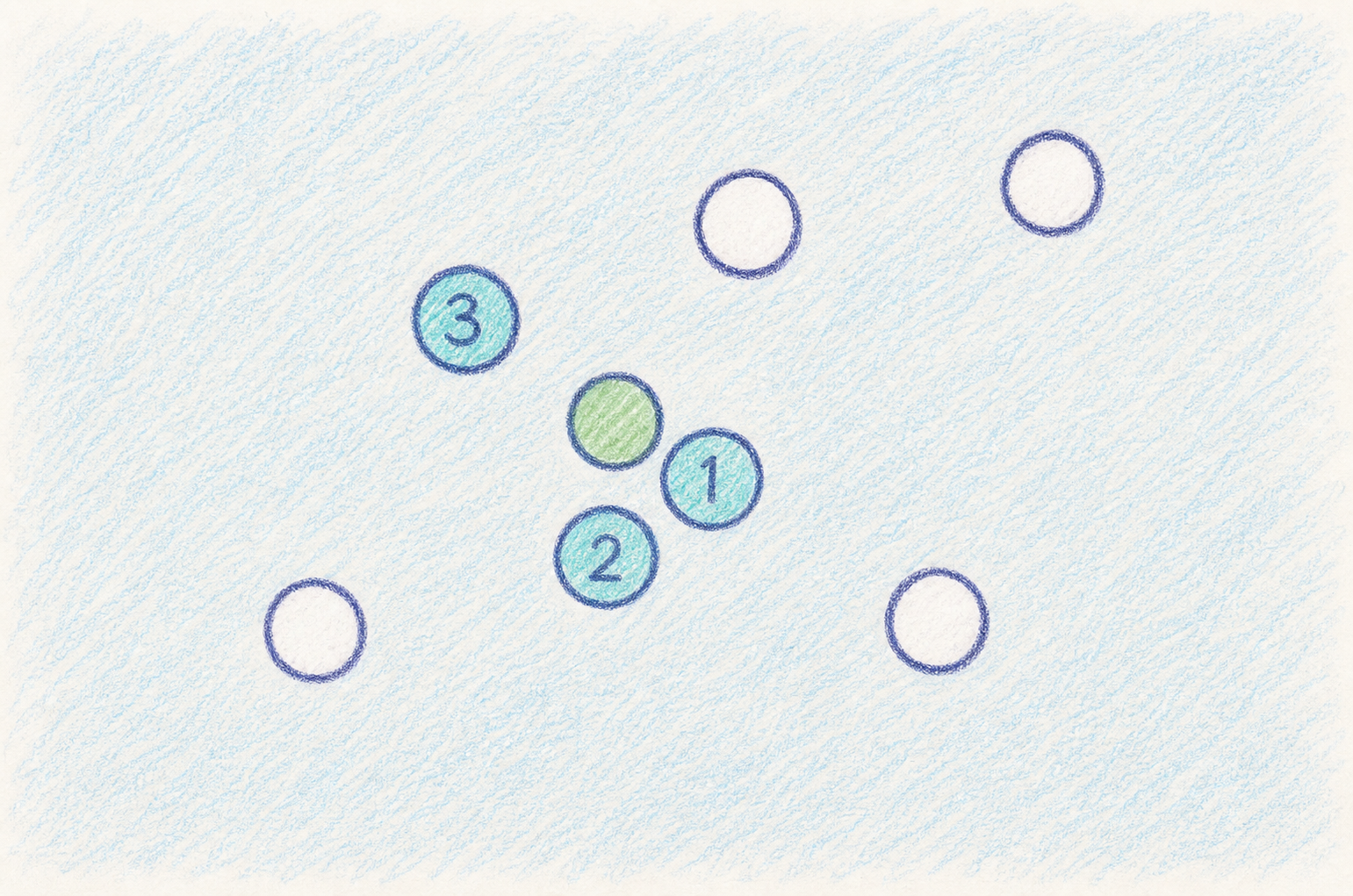
일반적인 검색에서는 상위 k개의 결과를 가져오는 top-k retrieval을 많이 사용합니다.
예를 들어 다음과 같이 설정할 수 있습니다.
top_k = 5이 경우 검색기는 가장 유사한 chunk 5개를 반환합니다. 하지만 문제는 5번째 결과가 실제로는 별로 관련이 없을 수도 있다는 점입니다.
Similarity Threshold는 검색 결과의 유사도 점수가 일정 기준보다 낮으면 제외하는 방식입니다.
score >= 0.75인 결과만 사용합니다.
장점
Similarity Threshold를 사용하면 관련성이 낮은 chunk가 LLM context에 들어가는 것을 줄일 수 있습니다. 불필요한 정보가 줄어들기 때문에 답변 품질이 안정될 수 있습니다.
단점
threshold를 너무 높게 설정하면 필요한 문서까지 제외될 수 있습니다. 반대로 너무 낮게 설정하면 효과가 줄어듭니다.
따라서 threshold는 고정값으로 정하기보다 실제 검색 로그와 평가 데이터셋을 기반으로 조정하는 것이 좋습니다.
6. Auto-cut: 적절한 지점에서 검색 결과 자르기
Auto-cut은 검색 결과를 단순히 top-k개 가져오는 대신, 유사도 점수의 변화나 결과 간 차이를 보고 적절한 지점에서 잘라내는 방식입니다.
예를 들어 검색 결과의 점수가 다음과 같다고 가정해보겠습니다.
1위: 0.91
2위: 0.89
3위: 0.87
4위: 0.62
5위: 0.59이 경우 1~3위는 서로 높은 관련성을 보이지만, 4위부터 점수가 크게 떨어집니다. Auto-cut은 이런 차이를 감지해 3위까지만 사용하는 방식입니다.
장점
Auto-cut은 질문마다 필요한 context 양이 다르다는 점을 반영할 수 있습니다. 어떤 질문은 2개의 chunk만으로 충분하고, 어떤 질문은 6개의 chunk가 필요할 수 있습니다.
고정된 top-k보다 유연하게 context를 구성할 수 있다는 점이 장점입니다.
주의할 점
점수 분포가 항상 명확하게 나뉘는 것은 아닙니다. 또한 embedding 모델이나 검색 방식에 따라 score scale이 다를 수 있으므로, auto-cut 기준을 도메인에 맞게 조정해야 합니다.
7. Multi-vector Retrieval: 하나의 문서를 여러 관점으로 검색하기
Multi-vector Retrieval은 하나의 문서나 chunk를 하나의 vector만으로 표현하지 않고, 여러 개의 vector로 표현하는 방식입니다.
일반적인 RAG에서는 하나의 chunk에 대해 하나의 embedding을 생성합니다. 하지만 복잡한 문서의 경우 하나의 vector만으로 모든 의미를 충분히 표현하기 어려울 수 있습니다.
예를 들어 하나의 문서가 다음 내용을 모두 포함한다고 가정해보겠습니다.
- 제품 개요
- 설치 방법
- 인증 설정
- 오류 해결
이 문서를 하나의 vector로만 표현하면 각 주제의 세부 의미가 희석될 수 있습니다. Multi-vector Retrieval은 문서의 여러 관점이나 하위 요소를 각각 vector로 표현해 검색 품질을 높이는 접근입니다.
활용 방식
Multi-vector Retrieval은 다음과 같은 방식으로 구현할 수 있습니다.
- 하나의 문서를 여러 chunk로 나누고 각 chunk를 embedding합니다.
- 문서의 제목, 요약, 본문을 각각 embedding합니다.
- 질문 생성 방식으로 문서가 답할 수 있는 가상의 질문들을 만들고 embedding합니다.
- 문서의 핵심 proposition을 추출해 각각 embedding합니다.
장점
Multi-vector Retrieval은 사용자의 질문이 문서의 특정 부분과만 관련될 때 유용합니다. 하나의 문서를 다양한 검색 진입점으로 표현하기 때문에 관련 문서를 찾을 가능성이 높아집니다.
단점
저장해야 할 vector 수가 증가합니다. 따라서 인덱스 크기, 검색 비용, 관리 복잡도가 늘어날 수 있습니다.
Retrieval Optimization 전략 비교
| 전략 | 핵심 역할 | 장점 | 주의점 | 적합한 경우 |
|---|---|---|---|---|
| Vector Search | 의미적으로 가까운 문서를 찾습니다 | 표현이 달라도 관련 문서를 찾을 수 있습니다 | 고유명사와 코드 검색에 약할 수 있습니다 | 일반적인 의미 기반 검색 |
| Keyword Search | 정확한 단어 일치로 찾습니다 | 에러 코드, 제품명, API 검색에 강합니다 | 표현이 다르면 놓칠 수 있습니다 | 정확한 용어가 중요한 검색 |
| Hybrid Search | vector와 keyword를 결합합니다 | 의미와 키워드를 함께 반영합니다 | 점수 결합 방식이 중요합니다 | 전문 용어가 섞인 질문 |
| Metadata Filtering | 조건에 맞는 문서만 검색합니다 | 검색 범위를 정확히 좁힙니다 | 메타데이터 품질에 의존합니다 | 최신성, 권한, 제품별 검색 |
| Similarity Threshold | 낮은 관련도 결과를 제외합니다 | 불필요한 context를 줄입니다 | 기준값 조정이 필요합니다 | 검색 결과 품질 관리 |
| Auto-cut | 점수 변화에 따라 결과 수를 조절합니다 | 질문별로 context 양을 유연하게 조절합니다 | score 분포에 민감합니다 | 고정 top-k가 비효율적인 경우 |
| Multi-vector Retrieval | 문서를 여러 vector로 표현합니다 | 다양한 관점에서 검색할 수 있습니다 | 저장 비용과 복잡도가 증가합니다 | 복잡한 문서, 긴 문서 |
Retrieval Optimization을 설계할 때의 체크리스트
검색 최적화를 설계할 때는 다음 질문을 먼저 확인하는 것이 좋습니다.
검색 방식 선택
- 사용자의 질문은 의미 기반 검색이 중요한가요?
- 정확한 키워드, 에러 코드, 제품명이 중요한가요?
- vector search와 keyword search를 함께 써야 하나요?
메타데이터 활용
- 문서에 제품명, 버전, 작성일, 문서 유형이 저장되어 있나요?
- 최신 문서만 검색해야 하는 경우가 있나요?
- 사용자 권한에 따라 검색 범위를 제한해야 하나요?
검색 결과 수 조절
- top-k 값을 고정해도 충분한가요?
- 관련성이 낮은 결과를 제외할 threshold가 필요한가요?
- 질문별로 검색 결과 수를 다르게 조절해야 하나요?
검색 품질 평가
- 실제 사용자 질문으로 검색 결과를 평가하고 있나요?
- 검색 결과에 정답 문서가 포함되는지 측정하고 있나요?
- 상위 결과가 중복 chunk로만 채워지지는 않나요?
- 검색 실패 사례를 로그로 남기고 있나요?
Retrieval Optimization의 한계
Retrieval Optimization은 RAG 품질을 크게 높일 수 있지만, 검색 단계만으로 모든 문제를 해결할 수는 없습니다.
먼저 원본 데이터와 chunk 품질이 낮으면 검색 최적화의 효과도 제한됩니다. 잘못 나뉜 chunk, 누락된 메타데이터, 중복 문서가 많다면 좋은 검색 결과를 얻기 어렵습니다.
또한 검색 전략이 복잡해질수록 운영 비용도 증가합니다. Hybrid Search, metadata filtering, multi-vector retrieval은 성능을 높일 수 있지만 인덱스 관리, score 조정, 평가 체계가 필요합니다.
마지막으로 검색 결과가 좋아도 LLM이 context를 제대로 사용하지 못하면 답변 품질이 낮아질 수 있습니다. 따라서 Retrieval Optimization은 Pre-retrieval, Post-retrieval, Generation 단계와 함께 전체 파이프라인 관점에서 설계해야 합니다.
마치며: Retrieval은 RAG의 근거를 선택하는 단계입니다
Retrieval Optimization은 RAG 시스템에서 가장 중요한 최적화 영역 중 하나입니다.
검색 단계는 LLM이 답변에 사용할 근거를 선택하는 과정입니다. 이 단계에서 관련 문서를 정확히 찾아오면 LLM은 더 좋은 답변을 생성할 수 있습니다. 반대로 검색 결과가 부정확하면 아무리 좋은 LLM을 사용해도 답변 품질은 제한됩니다.
핵심은 다음과 같습니다.
- Vector Search는 의미적으로 유사한 문서를 찾는 데 강합니다.
- Keyword Search는 정확한 용어와 코드 검색에 강합니다.
- Hybrid Search는 두 방식의 장점을 결합합니다.
- Metadata Filtering은 검색 범위를 더 정확하게 좁힙니다.
- Similarity Threshold와 Auto-cut은 관련성이 낮은 결과를 줄입니다.
- Multi-vector Retrieval은 복잡한 문서를 다양한 관점에서 검색할 수 있게 합니다.
결국 좋은 RAG는 좋은 검색에서 시작됩니다. 그리고 좋은 검색은 문서의 특성, 사용자의 질문 유형, 메타데이터, 검색 방식의 장단점을 함께 고려해 설계해야 합니다.
'AI' 카테고리의 다른 글
| 지구상에서 가장 친절한 RAG 06: 조직에서 RAG를 도입할 때 자주 묻는 질문들 (0) | 2026.06.03 |
|---|---|
| 지구상에서 가장 친절한 RAG 05: 검색된 근거를 더 잘 쓰는 방법 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 03: 검색 전에 질문을 최적화하는 방법 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 02: 청킹 전략은 왜 중요한가 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 01: 데이터 전처리가 검색 품질을 결정하는 이유 (0) | 2026.06.03 |