
시작하며
1M Context, LLM-Wiki, Ontology, NLM MCP 사이에서 무엇을 선택해야 할까요?RAG에 대한 논의는 여전히 뜨겁습니다. 한때 RAG는 LLM의 한계를 보완하는 가장 현실적인 방법처럼 보였습니다. 내부 문서를 검색해 답변에 활용하면 hallucination을 줄이고, 최신 정보를 반영하고, 조직 지식을 쉽게 활용할 수 있을 것처럼 보였기 때문입니다.
하지만 실제로 조직에서 RAG를 운영해보면 기대와 다른 지점이 금방 드러납니다.
구현 자체는 어렵지 않습니다. 문서를 넣고, chunk로 나누고, embedding을 만들고, vector database에 저장하고, 질문이 들어오면 유사한 chunk를 찾아 LLM에 넣으면 됩니다. 문제는 그 다음입니다.
"와, 문맥 참조가 되네?"에서 시작하지만, 운영 단계로 가면 "왜 이렇게 애매하지?", "왜 관련 없는 문서를 가져오지?", "왜 더 신뢰감 있는 틀린 답을 하지?"라는 질문을 마주하게 됩니다.
그래서 요즘 RAG에 대한 논의는 단순히 "RAG가 좋은가 나쁜가"가 아니라, "조직 환경에서 RAG를 어디까지, 어떤 방식으로 써야 하는가"로 옮겨가고 있습니다.
먼저 결론부터 말하면, RAG는 죽은 기술이 아닙니다
RAG의 hype가 내려간 것은 RAG가 쓸모없어졌기 때문이 아닙니다. 오히려 실제로 써보니 "잘 만들기 어렵다"는 사실이 드러났기 때문입니다.
RAG는 개념적으로는 단순합니다. 하지만 좋은 RAG를 만들려면 다음 요소들이 모두 맞아야 합니다.
- 원본 문서의 품질
- parsing 품질
- chunking 전략
- metadata 설계
- embedding 모델 선택
- retrieval 방식
- re-ranking 여부
- context post-processing
- prompt 설계
- 평가 데이터셋
- 운영 비용과 latency
- 권한 관리와 보안 정책
즉, RAG는 단순한 LLM 기능이 아니라 조직의 지식 검색 인프라에 가깝습니다.
개인이 몇 개의 PDF를 넣고 쓰는 것과, 조직 전체가 업무 문서·정책 문서·고객 문의·기술 문서를 기반으로 안정적인 답변 시스템을 운영하는 것은 전혀 다른 문제입니다.
질문 1. "그냥 1M context에 다 넣으면 안 되나요?"
긴 context window를 가진 모델이 등장하면서 가장 먼저 나오는 질문입니다.
"어차피 1M token까지 들어가면 그냥 문서를 통째로 넣으면 되는 거 아닌가요?"
개인 사용에서는 이 접근이 꽤 유용할 수 있습니다. 문서 몇 개를 넣고 한두 번 질문하는 상황이라면, 굳이 복잡한 RAG 파이프라인을 만들지 않아도 됩니다. 긴 context에 문서를 넣고 바로 질문하는 편이 더 빠르고 간단할 수 있습니다.
하지만 조직 환경에서는 이야기가 달라집니다.
1M context는 무료가 아닙니다
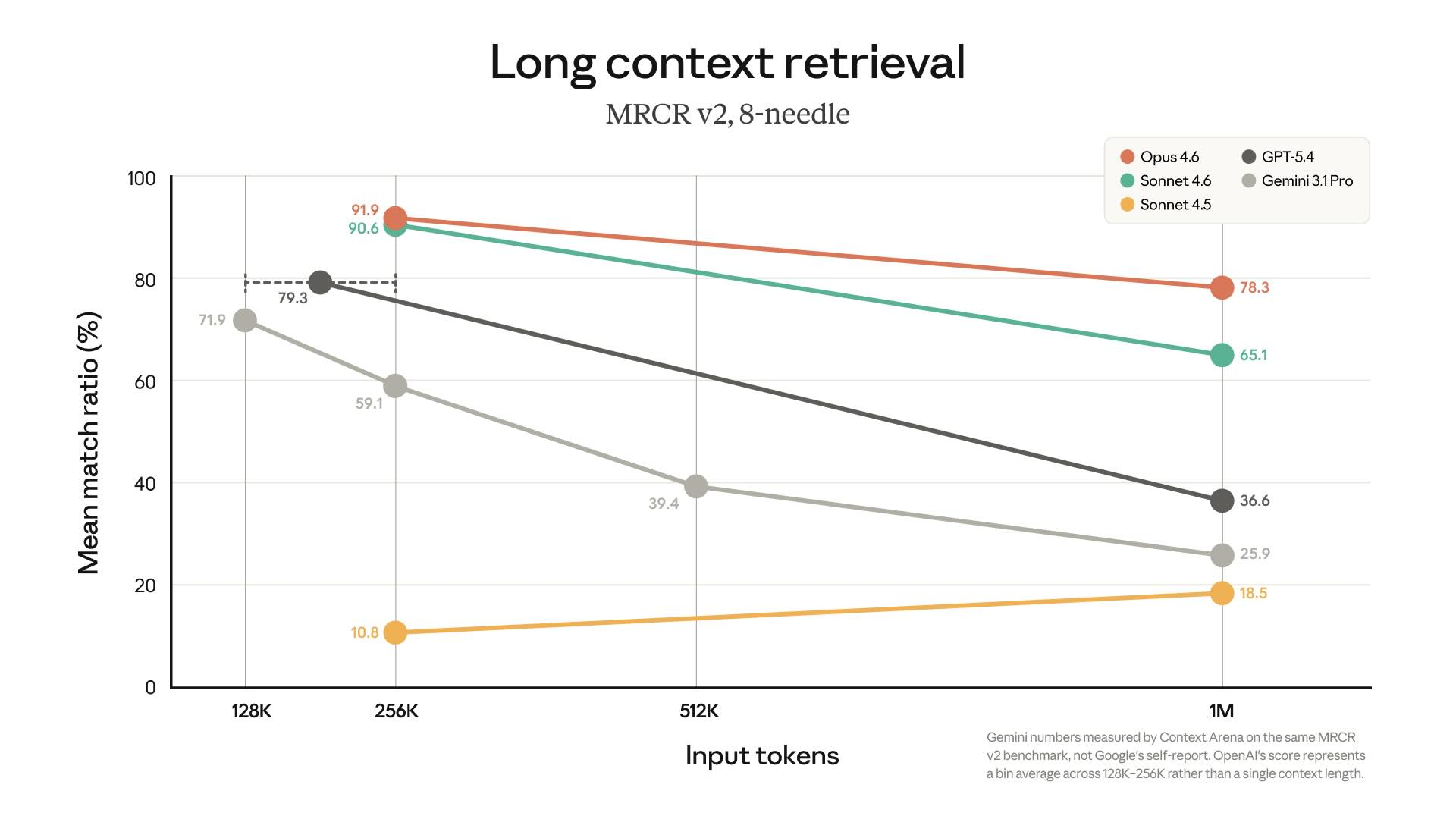
긴 context는 강력하지만 비용이 따릅니다. 토큰 비용, latency, 모델의 attention 부담, 반복 질의 비용이 모두 증가합니다.
예를 들어 문서 한 장을 1,000 token으로만 잡아도 500페이지 문서는 약 500,000 token입니다. 여기에 사용자의 질문, 추가 문서, 이전 대화, 시스템 프롬프트까지 들어가면 금방 context가 커집니다.
조직에서는 한 사람이 한 번 질문하는 것이 아니라, 여러 사용자가 반복적으로 질문합니다. 매번 큰 문서를 통째로 넣는 구조라면 비용은 선형적으로 누적됩니다.
개인 사용: 문서 몇 개를 한 번 넣고 질문합니다.
조직 사용: 여러 사람이 여러 문서를 반복적으로 질문합니다.조직 관점에서는 "한 번 가능한가?"보다 "반복적으로 운영 가능한가?"가 더 중요합니다.
긴 context는 항상 더 좋은 답을 보장하지 않습니다
또 하나의 문제는 긴 context에 넣었다고 해서 모델이 모든 정보를 균등하게 잘 활용하지는 않는다는 점입니다.
긴 문서 안에서 필요한 정보를 정확히 찾고, 서로 다른 문서의 조건을 비교하고, 최신 문서와 오래된 문서를 구분하고, 사용자의 질문과 연결하는 일은 여전히 어렵습니다.
특히 법률, 세무, 노무, 의료, 감리, 공공 지침처럼 단어 하나가 의미를 바꾸는 영역에서는 "대충 읽고 요약"하는 방식이 위험합니다.
사용자의 질문이 다음과 같다고 가정해보겠습니다.
이번 집행 계획이 혁신법 예산 사용 지침의 어느 조항에 해당하나요?이 경우 단순히 지침서 전체를 넣는 것만으로 충분하지 않습니다. 사용자의 집행 계획 문서도 함께 읽어야 하고, 지침서의 조항과 비교해야 하며, 예외 조건도 확인해야 합니다.
긴 context는 재료를 많이 넣는 방식입니다. 하지만 조직이 원하는 것은 "많이 넣는 것"이 아니라 "필요한 근거를 정확히 찾아 쓰는 것"입니다.
1M context와 RAG는 경쟁 관계가 아니라 선택지입니다
긴 context는 RAG를 완전히 대체한다기보다, 특정 상황에서 RAG보다 단순한 대안이 될 수 있습니다.
다음 상황에서는 긴 context 접근이 적합할 수 있습니다.
- 문서 수가 적습니다.
- 질문 횟수가 적습니다.
- 개인 또는 소규모 분석입니다.
- 보안과 비용 문제가 크지 않습니다.
- 답변의 재현성과 운영성이 덜 중요합니다.
반면 다음 상황에서는 RAG가 더 적합합니다.
- 문서가 많고 지속적으로 업데이트됩니다.
- 여러 사용자가 반복적으로 질문합니다.
- 문서 접근 권한을 관리해야 합니다.
- 출처 추적이 필요합니다.
- 비용과 latency를 관리해야 합니다.
- 검색 품질을 평가하고 개선해야 합니다.
조직에서는 context window의 크기보다, 검색 가능한 지식 인프라를 어떻게 설계할지가 더 중요합니다.
질문 2. "그럼 LLM-Wiki처럼 인덱싱해서 쓰는 게 더 낫지 않나요?"
두 번째 질문은 문서를 LLM이 읽기 좋은 형태로 다시 정리한 뒤 사용하는 방식에 대한 것입니다.
예를 들어 원본 문서를 그대로 RAG에 넣는 대신, LLM이 문서를 읽고 markdown 구조로 정리하거나, 목차를 만들거나, 요약본을 생성해 "LLM-friendly wiki"를 만드는 방식입니다.
이 접근은 분명 장점이 있습니다.
- 문서 구조가 정리됩니다.
- 목차가 생깁니다.
- 검색할 때 필요한 토큰이 줄어들 수 있습니다.
- 사람이 읽기에도 좋아집니다.
- LLM이 이해하기 쉬운 형태가 됩니다.
하지만 조직 환경에서는 중요한 질문이 남습니다.
요약하거나 다시 쓴 문서가 원본을 얼마나 보존하나요?
LLM-Wiki는 본질적으로 rewrite입니다
LLM-Wiki 방식은 원본 문서를 LLM이 다시 쓰는 과정에 가깝습니다. 이때 정보가 압축되고, 표현이 바뀌고, 일부 내용이 생략될 수 있습니다.
일반적인 지식 문서나 블로그 글이라면 큰 문제가 아닐 수 있습니다. 하지만 법률, 세무, 노무, 의료, 감리, 보안 정책처럼 정확한 문구가 중요한 영역에서는 위험해집니다.
예를 들어 원문에는 다음과 같은 문장이 있다고 가정해보겠습니다.
신청일로부터 30일 이내에 제출해야 하며, 부득이한 사유가 있는 경우 15일 범위에서 연장할 수 있습니다.이를 요약하면서 다음처럼 바뀌면 문제가 생깁니다.
신청 후 일정 기간 내 제출해야 하며, 필요 시 연장할 수 있습니다.사람이 보기에는 자연스러운 요약이지만, 중요한 숫자와 조건이 사라졌습니다. 조직 업무에서는 이런 생략이 치명적일 수 있습니다.
요약은 비용을 줄이지만 검증 비용을 만듭니다
LLM-Wiki 방식은 검색 비용을 줄일 수 있습니다. 하지만 그 대신 검증 비용이 생깁니다.
- 어떤 정보가 생략되었나요?
- 숫자와 조건이 보존되었나요?
- 문서의 법적 의미가 바뀌지 않았나요?
- 최신 원문과 동기화되고 있나요?
- 원문 출처로 다시 추적할 수 있나요?
결국 요약본을 만들었더라도 중요한 업무에서는 원문을 다시 확인해야 합니다. 그렇다면 "요약본만 믿고 답변해도 되는가?"라는 문제가 남습니다.
조직에서는 LLM-Wiki를 쓰더라도 원문 보존과 출처 추적이 함께 설계되어야 합니다.
LLM-Wiki는 RAG의 대체재가 아니라 전처리 전략일 수 있습니다
LLM-Wiki 방식은 RAG를 대체한다기보다, RAG의 전처리 또는 보조 인덱스 전략으로 보는 것이 더 현실적입니다.
예를 들어 다음과 같이 사용할 수 있습니다.
원문 문서 → 구조화된 목차 생성
원문 문서 → 섹션별 요약 생성
원문 문서 → 핵심 질문 생성
원문 문서 → 원문 chunk와 요약 chunk를 함께 인덱싱이렇게 하면 검색 시 요약본을 통해 넓게 찾고, 최종 답변에는 원문 chunk를 함께 제공할 수 있습니다.
중요한 것은 요약본이 원문을 대체하지 않도록 설계하는 것입니다.
질문 3. "그거 톨로지보다 못한 거 아닌가요?"
세 번째 질문은 RAG와 ontology의 비교입니다.
온톨로지는 도메인의 개념, 관계, 속성을 명시적으로 정의하는 방식입니다. 잘 만들어진 ontology는 강력합니다. 개념 간 관계를 구조화할 수 있고, 추론도 가능하며, 조직 지식을 체계적으로 관리할 수 있습니다.
하지만 문제는 "잘 만들어진 ontology"를 만드는 것이 매우 어렵다는 점입니다.
온톨로지에 대해서는 https://amazingsyp.github.io/pokemon-ontology/ 를 참고해주세요.온톨로지는 합의 비용이 큽니다
조직에서 ontology를 만들려면 단순히 엔지니어가 schema를 설계하는 것으로 끝나지 않습니다.
해당 도메인의 전문가들이 다음에 대해 합의해야 합니다.
- 어떤 개념을 정의할 것인가요?
- 개념 간 관계는 어떻게 표현할 것인가요?
- 문서 내부 구조에 적용할 것인가요?
- 문서 간 관계에 적용할 것인가요?
- 예외 케이스는 어떻게 처리할 것인가요?
- 부서마다 다른 용어는 어떻게 통합할 것인가요?
개인 지식 관리에서는 자신만 이해하면 되므로 ontology를 자유롭게 만들 수 있습니다. 하지만 조직에서는 여러 사람이 같은 의미로 이해하고 사용할 수 있어야 합니다.
이 합의가 없으면 ontology는 오히려 검색보다 못한 결과를 만들 수 있습니다.
목적 없는 온톨로지는 텍스트 검색보다 못할 수 있습니다
온톨로지는 나쁜 기술이 아닙니다. 문제는 목적 없이 도입하는 것입니다.
"전사 지식을 ontology로 만들자"는 말은 멋있어 보입니다. 하지만 어떤 문제를 해결하려는지 명확하지 않다면, 구조화 비용만 크고 실효성은 낮을 수 있습니다.
예를 들어 다음 두 질문은 전혀 다릅니다.
전사 문서를 모두 ontology로 만들 수 있을까요?고객지원팀의 장애 유형, 원인, 해결 절차 관계를 구조화해 응답 시간을 줄일 수 있을까요?두 번째 질문은 훨씬 현실적입니다. 특정 부서, 특정 목적, 특정 데이터 범위를 대상으로 하기 때문입니다.
RAG를 먼저 해보고, 필요한 부분에 ontology를 적용하는 편이 현실적입니다
조직에서 ontology를 고려한다면 처음부터 전사적으로 시작하기보다, 작은 범위에서 RAG를 먼저 적용해보는 것이 좋습니다.
예를 들어 한 부서의 문서를 대상으로 RAG를 구축하고 운영해보면 다음을 알 수 있습니다.
- 어떤 질문이 자주 들어오나요?
- 어떤 문서가 자주 검색되나요?
- 어떤 용어가 혼동되나요?
- 어떤 관계가 반복적으로 필요하나요?
- 어떤 metadata가 검색 품질에 영향을 주나요?
이 경험을 바탕으로 필요한 관계만 ontology나 knowledge graph 형태로 구조화하는 것이 현실적입니다.
즉, 순서는 다음이 좋습니다.
작은 범위의 RAG 도입
↓
검색 로그와 실패 사례 분석
↓
반복되는 개념과 관계 도출
↓
목적 중심의 소규모 ontology 설계
↓
RAG와 함께 활용온톨로지는 RAG의 적이 아닙니다. 하지만 RAG보다 먼저 전사적으로 도입할 만능 해법도 아닙니다.
질문 4. "굳이 구현하지 말고 NLM MCP 같은 걸 쓰면 안 되나요?"
네 번째 질문은 직접 구현할 필요가 있느냐는 질문입니다.
개인 사용에서는 NotebookLM이나 유사한 managed tool, MCP 기반 연결 방식이 충분히 좋은 선택일 수 있습니다. 문서를 올리고 질문하고, 필요한 답을 빠르게 얻는 용도라면 직접 RAG를 만들 이유가 없습니다.
하지만 조직에서는 다시 다른 질문이 생깁니다.
- 데이터를 외부 서비스에 올려도 되나요?
- 문서 접근 권한은 어떻게 통제하나요?
- 질문 로그와 답변 로그는 어디에 저장되나요?
- 민감 정보는 어떻게 처리되나요?
- 조직의 보안 기준을 만족하나요?
- 비용과 사용량을 관리할 수 있나요?
- 내부 시스템과 연동할 수 있나요
조직에서 AI 도구를 도입할 때는 성능뿐 아니라 governance가 중요합니다.
Managed tool은 편하지만 통제 범위가 제한될 수 있습니다
Managed tool은 빠르게 쓸 수 있다는 장점이 있습니다. 복잡한 parsing, indexing, retrieval, summarization을 직접 구현하지 않아도 됩니다.
하지만 조직 환경에서는 다음과 같은 제약이 문제가 될 수 있습니다.
- 데이터 반출 정책
- 권한별 문서 접근 제어
- 감사 로그
- 사내 인증 연동
- 비용 통제
- 답변 품질 평가
- 장애 대응
- 커스텀 retrieval 전략 적용
개인이나 소규모 팀에서는 managed tool이 최적일 수 있습니다. 하지만 전사 서비스나 고객 응대 시스템처럼 운영 책임이 필요한 경우에는 직접 구축 또는 내부 통제 가능한 managed RAG가 필요할 수 있습니다.
BM25 전수 검색은 왜 조심해야 할까요?
Threads 논의에서는 BM25로 거의 전수 검색에 가깝게 찾는 방식도 언급됩니다. BM25는 강력한 키워드 기반 검색 방식입니다. 특히 정확한 단어, 코드, 고유명사 검색에는 여전히 매우 유용합니다.
하지만 조직의 모든 텍스트 데이터를 메모리에 올려놓고 매번 넓게 검색하는 방식은 운영 관점에서 위험할 수 있습니다.
개인 노트북에서는 가능해 보이는 방식도 서버에서는 다릅니다.
- 여러 사용자가 동시에 검색합니다.
- 문서량이 계속 늘어납니다.
- 메모리와 CPU 사용량이 증가합니다.
- latency가 불안정해집니다.
- 장애가 전체 서비스에 영향을 줄 수 있습니다.
따라서 BM25는 버릴 기술이 아니라, 적절히 섞어야 하는 기술입니다. 실제 RAG에서는 vector search와 BM25를 결합한 hybrid search가 자주 사용됩니다.
의미 기반 검색이 필요한 질문 → Vector Search
정확한 용어 검색이 필요한 질문 → BM25 / Keyword Search
둘 다 필요한 질문 → Hybrid Search중요한 것은 "전부 다 읽으면 정확하다"가 아니라, "운영 가능한 방식으로 충분히 정확하게 찾는다"입니다.
결국 RAG는 구현이 쉬운 기술이 아니라 운영이 어려운 시스템입니다
RAG는 데모를 만들기는 쉽습니다. 하지만 조직에서 잘 운영하기는 어렵습니다.
좋은 RAG를 만들려면 다음 단계가 필요합니다.
1. 작은 범위에서 시작해야 합니다
처음부터 전사 RAG를 목표로 하면 실패할 가능성이 높습니다.
문서 형식도 다르고, 부서별 용어도 다르고, 권한도 다르고, 질문 유형도 다르기 때문입니다.
먼저 하나의 부서, 하나의 업무, 하나의 문서군에서 시작하는 것이 좋습니다.
예를 들어 다음처럼 시작할 수 있습니다.
고객지원팀의 FAQ와 장애 대응 문서
인사팀의 휴가·근태 규정
개발팀의 API 문서
보안팀의 VPN·계정 정책작은 범위에서 검색 실패 사례를 모으고, chunking과 metadata를 개선하고, 평가 질문을 만들면서 점진적으로 확장해야 합니다.
2. 문서 전처리가 가장 먼저입니다
RAG 품질은 원본 문서 품질에 크게 좌우됩니다.
PDF에서 텍스트가 깨지고, 표가 무너지고, header와 footer가 반복되고, 오래된 문서와 최신 문서가 섞여 있다면 retrieval만 개선해서는 한계가 있습니다.
따라서 RAG의 첫 단계는 model tuning이 아니라 data pre-processing입니다.
- 문서를 정확히 parsing합니다.
- header, footer, 중복 문구를 제거합니다.
- 제목, 섹션, 표 구조를 보존합니다.
- source, version, date, owner 같은 metadata를 저장합니다.
- chunking 전략을 문서 유형에 맞게 선택합니다.
RAG를 잘하려면 문서를 LLM이 잘 읽을 수 있게 만드는 작업이 선행되어야 합니다.
3. Retrieval은 한 가지 방식만 쓰지 않는 편이 좋습니다
조직 문서는 질문 유형이 다양합니다.
어떤 질문은 의미 기반 검색이 중요합니다.
비밀번호를 잊었을 때 어떻게 해야 하나요?어떤 질문은 정확한 키워드 검색이 중요합니다.
ERR_AUTH_401 오류 해결 방법 알려줘.어떤 질문은 메타데이터 필터링이 중요합니다.
2025년 최신 보안 정책 기준으로 알려줘.따라서 실제 운영에서는 vector search, keyword search, hybrid search, metadata filtering, re-ranking을 함께 고려해야 합니다.
4. 평가셋 없이는 개선할 수 없습니다
RAG를 운영하다 보면 "검색이 좋아진 것 같다"는 느낌만으로는 부족합니다.
조직에서는 평가 가능한 질문 세트가 필요합니다.
예를 들어 다음과 같은 데이터가 있어야 합니다.
- 실제 사용자가 자주 묻는 질문
- 정답에 필요한 문서 또는 chunk
- 허용 가능한 답변 예시
- 반드시 포함해야 하는 조건
- 잘못된 답변 사례
이 평가셋을 기반으로 chunking, retrieval, re-ranking, prompt를 비교해야 합니다.
RAG는 한 번 구축하고 끝나는 시스템이 아니라, 검색 로그와 실패 사례를 기반으로 계속 개선하는 시스템입니다.
5. 조직에서는 권한과 보안이 핵심입니다
개인 RAG에서는 모든 문서를 내가 볼 수 있습니다. 하지만 조직 RAG에서는 그렇지 않습니다.
부서별 문서, 인사 문서, 계약 문서, 고객 정보, 보안 정책은 접근 권한이 다릅니다. RAG가 검색 과정에서 권한을 무시하면 심각한 문제가 됩니다.
따라서 조직 RAG에는 다음이 필요합니다.
- 사용자별 문서 접근 제어
- 문서별 권한 metadata
- 검색 단계의 permission filtering
- 질문·답변 로그 관리
- 민감 정보 마스킹
- 감사 가능성
조직 RAG는 단순한 검색 챗봇이 아니라, 보안과 governance가 포함된 지식 시스템입니다.
마치며: RAG는 만능도 아니고, 폐기할 기술도 아닙니다
RAG는 한때 지나치게 hype를 받았습니다. "문서만 넣으면 조직 지식이 AI로 바뀐다"는 기대가 있었습니다. 하지만 실제로는 문서 전처리, chunking, retrieval, 권한 관리, 평가셋, 운영 비용이라는 현실적인 문제가 있었습니다.
그렇다고 RAG가 쓸모없어진 것은 아닙니다. 오히려 지금은 RAG를 더 현실적으로 봐야 할 시점입니다.
결국 중요한 것은 특정 기술을 무조건 선택하거나 버리는 것이 아닙니다. 조직의 데이터, 질문 유형, 보안 기준, 비용 구조, 운영 역량에 맞게 적재적소에 사용하는 것입니다.
RAG를 잘 쓰고 싶다면 먼저 작은 범위에서 시작해야 합니다. 한 부서의 문서로 실제 질문을 처리해보고, 실패 사례를 모으고, 전처리와 retrieval을 개선해야 합니다. 그 과정에서 필요한 경우 LLM-Wiki, ontology, managed tool, hybrid search를 함께 조합하면 됩니다.
좋은 RAG는 거대한 기술 선언에서 시작되지 않습니다.
좋은 RAG는 작은 업무 문제를 정확히 정의하고, 그 문제를 해결하는 검색 가능한 지식 시스템을 차근차근 만드는 것에서 시작됩니다.
'AI' 카테고리의 다른 글
| 지구상에서 가장 친절한 RAG 05: 검색된 근거를 더 잘 쓰는 방법 (0) | 2026.06.03 |
|---|---|
| 지구상에서 가장 친절한 RAG 04: 더 좋은 근거를 찾는 검색 전략 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 03: 검색 전에 질문을 최적화하는 방법 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 02: 청킹 전략은 왜 중요한가 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 01: 데이터 전처리가 검색 품질을 결정하는 이유 (0) | 2026.06.03 |