
시작하며
RAG 시스템에서 좋은 답변을 만들기 위해서는 먼저 관련 문서를 잘 찾아야 합니다. 하지만 검색만 잘한다고 항상 좋은 답변이 만들어지는 것은 아닙니다.
검색 결과에는 질문과 관련성이 높은 chunk도 있지만, 덜 중요한 chunk, 중복된 chunk, 순서가 어색한 chunk, 너무 긴 context도 함께 포함될 수 있습니다. 이 상태로 그대로 LLM에 전달하면 LLM은 불필요한 정보에 주의를 빼앗기거나, 중요한 정보를 충분히 활용하지 못할 수 있습니다.
이 문제를 해결하기 위한 단계가 Post-retrieval Optimization입니다.
Post-retrieval Optimization은 검색이 끝난 뒤, LLM에 context를 전달하기 전에 검색 결과를 다시 정리하고 최적화하는 과정입니다. 쉽게 말하면 검색된 문서를 그대로 쓰지 않고, 답변 생성에 더 적합한 형태로 다듬는 단계입니다.
Post-retrieval Optimization이란 무엇인가요?
Post-retrieval Optimization은 RAG 파이프라인에서 retrieval 이후에 적용되는 최적화 기법입니다.
일반적인 RAG 흐름은 다음과 같습니다.
사용자 질문
↓
Query 최적화
↓
검색 Retrieval
↓
검색 결과 정리 및 최적화
↓
Prompt 구성
↓
LLM 답변 생성여기서 Post-retrieval Optimization은 검색 결과 정리 및 최적화에 해당합니다.
검색 단계가 관련 후보 문서를 찾는 과정이라면, post-retrieval 단계는 그 후보들 중에서 어떤 정보를 우선적으로 사용할지, 어떤 정보를 제거할지, 어떤 순서로 LLM에 넣을지 결정하는 과정입니다.
왜 검색 이후 최적화가 필요한가요?
검색 결과는 항상 완벽하지 않습니다. 검색기는 질문과 관련 있을 가능성이 높은 chunk를 가져오지만, 그 결과가 바로 LLM에게 최적의 context라는 뜻은 아닙니다.
검색 이후에 다음과 같은 문제가 자주 발생합니다.
- 관련성이 낮은 chunk가 함께 검색됩니다.
- 비슷한 내용의 chunk가 여러 개 반복됩니다.
- 중요한 chunk가 아래 순위에 밀려 있습니다.
- 문서 순서가 답변 흐름과 맞지 않습
- context가 너무 길어 LLM 입력 토큰을 낭비합니다.
- 서로 충돌하는 정보가 함께 들어옵니다.
- 최신 문서와 오래된 문서가 섞여 있습니다.
Post-retrieval Optimization은 이런 문제를 줄여 LLM이 더 좋은 context를 바탕으로 답변하도록 돕습니다.
Post-retrieval Optimization의 핵심 방향
Post-retrieval Optimization은 크게 네 가지 방향으로 이해할 수 있습니다.
- 검색 결과의 순서를 다시 조정합니다.
- 검색된 context를 정리하고 압축합니다.
- LLM이 context를 잘 사용하도록 prompt를 설계합니다.
- 필요하다면 LLM 자체를 도메인에 맞게 조정합니다.
이 방향은 다음 기법으로 연결됩니다.
- Re-ranking
- Context Post-processing
- Prompt Engineering
- LLM Fine-tuning
이제 각 기법을 하나씩 살펴보겠습니다.
1. Re-ranking: 검색 결과의 순서를 다시 정렬하기
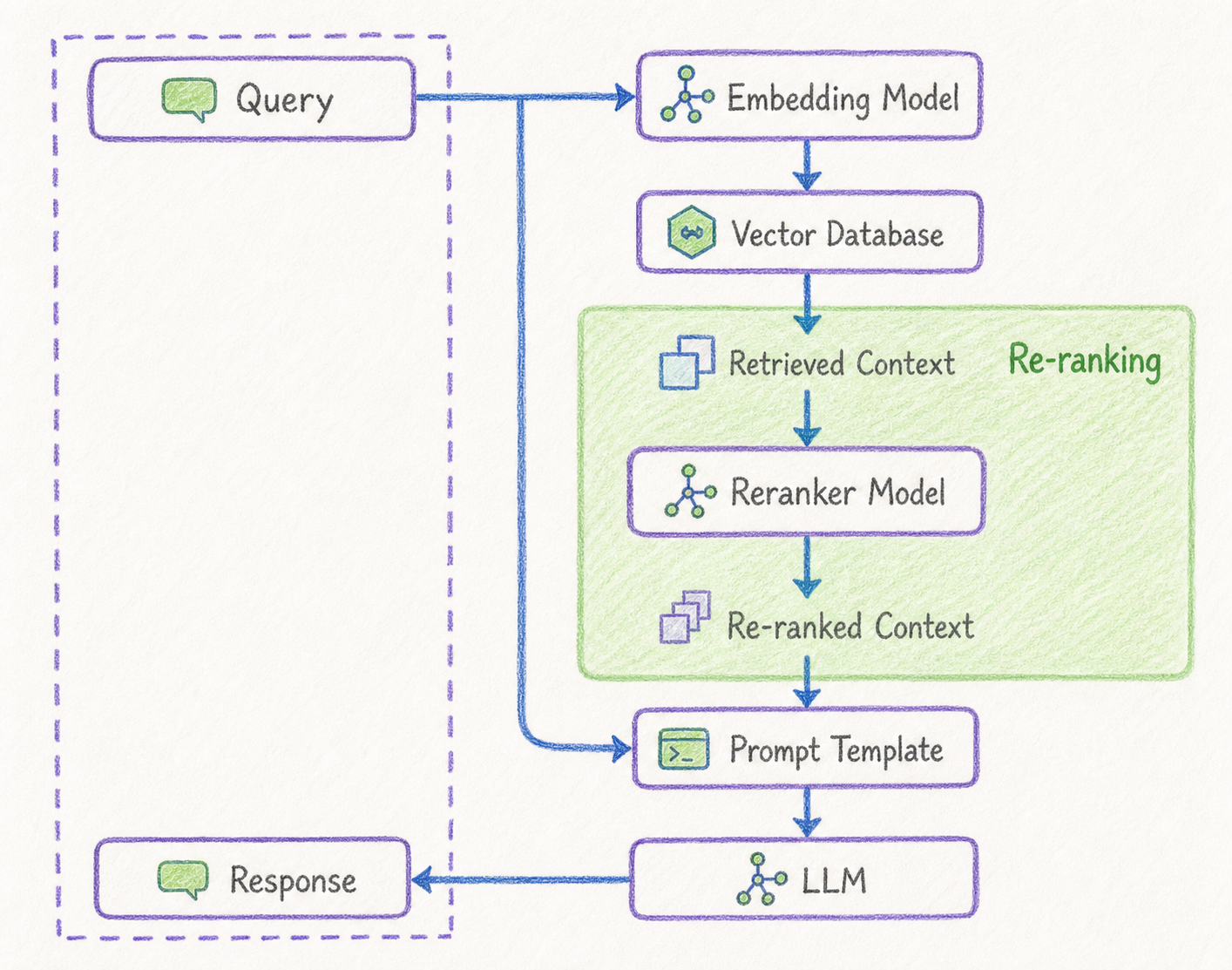
Re-ranking은 retrieval 단계에서 가져온 후보 chunk들의 순서를 다시 평가하고 재정렬하는 기법입니다.
일반적인 retrieval은 빠른 검색을 위해 vector similarity나 keyword score를 사용합니다. 이 방식은 후보 문서를 빠르게 찾는 데 유리하지만, 최종 관련성 판단까지 완벽하게 수행하지는 못할 수 있습니다.
Re-ranking은 검색된 후보들을 대상으로 query와 chunk의 관련성을 더 정교하게 다시 계산합니다.
Re-ranking은 왜 필요한가요?
예를 들어 사용자가 다음과 같이 질문했다고 가정해보겠습니다.
관리자 계정에서 SSO 로그인 오류가 발생했을 때 해결 방법은 무엇인가요?검색 결과로 다음 chunk들이 반환될 수 있습니다.
1. SSO 설정 개요
2. 관리자 계정 권한 설정 방법
3. SSO 로그인 오류 해결 절차
4. 일반 로그인 오류 FAQ
5. 계정 생성 방법초기 검색 결과에서는 1번이나 2번이 상위에 있을 수 있습니다. 하지만 실제로 가장 적합한 chunk는 3번입니다.
Re-ranking은 이 후보들을 다시 평가해 "SSO 로그인 오류 해결 절차”를 더 위로 올리는 역할을 합니다.
Re-ranking 방식
Re-ranking에는 여러 방식이 있습니다.
Cross-encoder 기반 Re-ranking
Cross-encoder는 query와 chunk를 함께 입력으로 넣고 관련성 점수를 계산하는 방식입니다. query와 문서를 따로 embedding한 뒤 유사도를 계산하는 bi-encoder 방식보다 더 정교하게 관계를 판단할 수 있습니다.
장점은 관련성 판단이 정확하다는 점입니다. 단점은 후보 chunk마다 모델 추론이 필요하므로 비용과 latency가 증가한다는 점입니다.
LLM 기반 Re-ranking
LLM에게 검색 결과 목록을 주고, 질문에 가장 적합한 순서로 재정렬하게 할 수도 있습니다.
예를 들어 LLM에게 다음과 같이 지시할 수 있습니다.
다음 검색 결과를 사용자 질문에 답변하는 데 유용한 순서로 정렬하세요.이 방식은 복잡한 의미 판단에 유리하지만, 비용이 크고 결과 일관성 관리가 필요합니다.
Rule 기반 Re-ranking
도메인 규칙을 적용해 검색 결과의 순서를 조정할 수도 있습니다.
예를 들어 최신 문서를 우선하거나, 공식 문서를 우선하거나, 특정 권한 범위의 문서를 우선하는 방식입니다.
Re-ranking의 장점과 주의점
Re-ranking의 장점은 검색 결과의 precision을 높일 수 있다는 것입니다. 특히 top-k 검색에서 관련 후보는 포함되었지만 순서가 좋지 않은 경우 큰 효과를 볼 수 있습니다.
다만 re-ranking은 검색되지 않은 문서를 새로 찾아오는 기법이 아닙니다. 초기 retrieval 단계에서 정답 후보가 아예 빠졌다면 re-ranking만으로는 해결할 수 없습니다.
따라서 re-ranking은 recall이 충분한 retrieval 결과 위에서 precision을 높이는 방식으로 이해하는 것이 좋습니다.
2. Context Post-processing: 검색된 context를 정리하고 압축하기
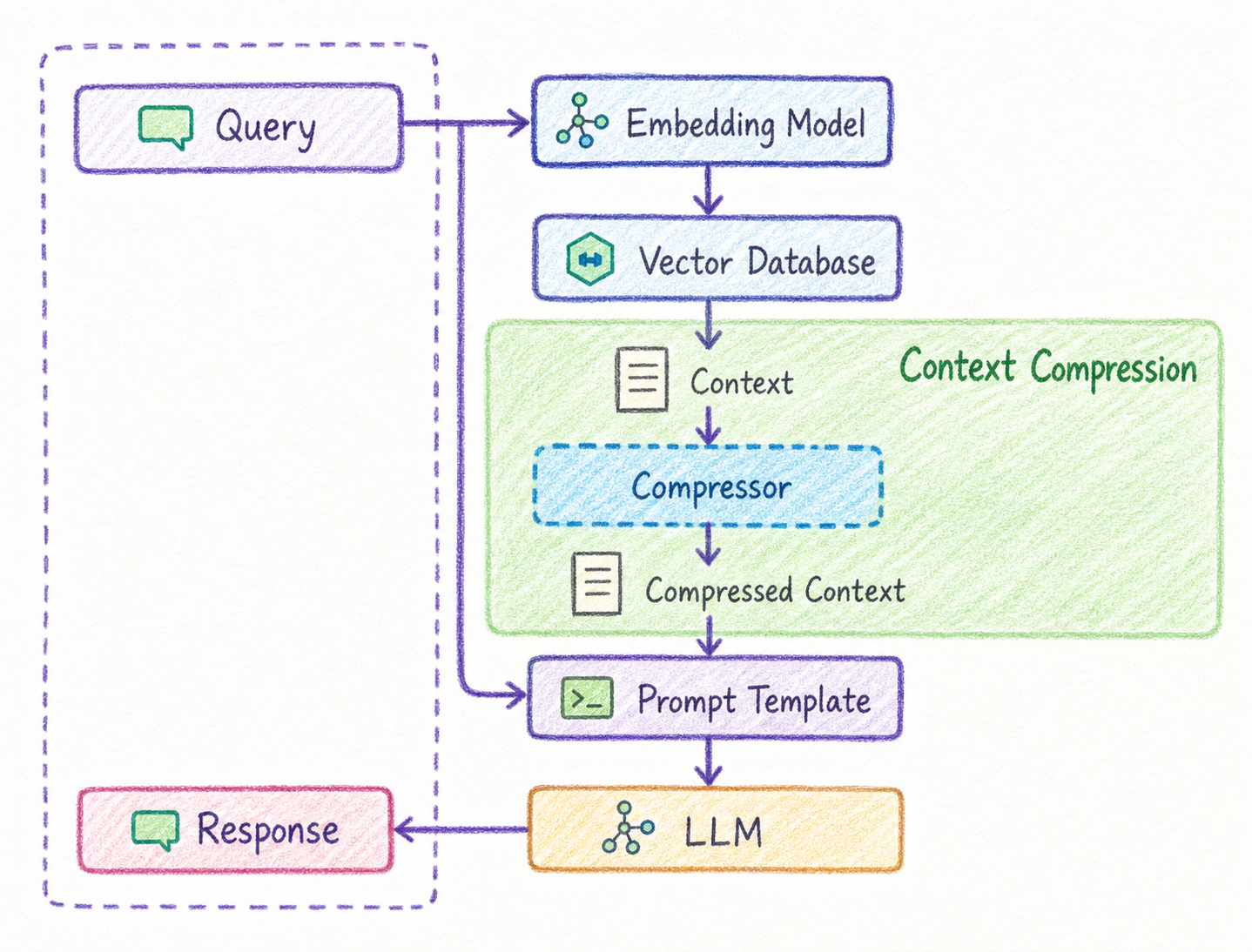
Context Post-processing은 검색된 chunk들을 LLM에 넣기 전에 정리하는 과정입니다.
검색 결과는 그대로 사용하기에는 길거나 중복되거나 불필요한 내용이 섞여 있을 수 있습니다. Context Post-processing은 이런 검색 결과를 답변 생성에 적합한 형태로 다듬습니다.
대표적인 작업은 다음과 같습니다.
- 중복 chunk 제거
- 관련성이 낮은 문장 제거
- chunk 순서 재배치
- 긴 context 요약 또는 압축
- 충돌하는 정보 정리
- 출처 정보 보존
- 문서 간 연결 관계 정리
중복 제거
RAG에서는 chunk overlap을 사용하거나 비슷한 문서가 여러 개 있을 때 중복된 내용이 반복 검색될 수 있습니다.
예를 들어 검색 결과가 다음과 같을 수 있습니다.
1. 비밀번호 재설정 방법
2. 비밀번호 재설정 절차
3. 계정 비밀번호 초기화 방법세 chunk가 거의 같은 내용을 담고 있다면 모두 LLM에 넣을 필요는 없습니다. 중복을 줄이면 LLM 입력 토큰을 절약하고, 다양한 근거를 더 많이 넣을 수 있습니다.
Context 압축
검색 결과가 너무 길면 LLM의 context window를 많이 차지합니다. 이때 중요한 문장만 남기거나, chunk를 짧게 요약하는 방식으로 context를 압축할 수 있습니다.
예를 들어 긴 장애 대응 문서에서 사용자의 질문과 직접 관련된 원인, 확인 항목, 해결 절차만 추출할 수 있습니다.
원문 chunk: 장애 개요, 영향 범위, 로그 예시, 원인, 해결 절차, 사후 조치 포함
압축 context: 원인, 확인할 로그, 해결 절차만 추출Context 압축은 토큰 비용을 줄이고 LLM이 핵심 정보에 집중하도록 도와줍니다.
다만 압축 과정에서 중요한 근거가 삭제되지 않도록 주의해야 합니다.
Context 순서 재배치
LLM은 context에 들어온 정보의 순서에 영향을 받을 수 있습니다. 가장 중요한 근거가 너무 뒤에 있거나, 배경 설명과 결론이 뒤섞여 있으면 답변 품질이 낮아질 수 있습니다.
따라서 context를 다음과 같이 재배치할 수 있습니다.
1. 질문에 가장 직접적으로 답하는 chunk
2. 보조 근거 chunk
3. 예외 사항 또는 주의 사항
4. 출처와 세부 설명질문이 절차를 묻는 경우에는 단계 순서대로 정렬하는 것이 좋고, 비교를 묻는 경우에는 비교 대상별로 context를 묶는 것이 좋습니다.
충돌 정보 정리
여러 문서에서 서로 다른 정보를 검색하는 경우도 있습니다.
예를 들어 하나의 문서는 "2023년 기준 정책"을 설명하고, 다른 문서는 "2025년 개정 정책"을 설명할 수 있습니다. 두 문서를 그대로 LLM에 넣으면 답변이 모호해질 수 있습니다.
이 경우 metadata를 활용해 최신 문서를 우선하거나, prompt에서 충돌하는 정보가 있을 경우 최신 문서 또는 공식 문서를 우선하라고 지시해야 합니다.
3. Prompt Engineering: 검색된 context를 잘 쓰도록 지시하기
Post-retrieval 단계에서 prompt engineering은 매우 중요합니다.
검색 결과가 좋아도 LLM이 그 정보를 제대로 사용하지 않으면 답변 품질은 낮아질 수 있습니다. Prompt Engineering은 LLM이 검색된 context를 어떻게 사용해야 하는지 명확히 알려주는 역할을 합니다.
RAG Prompt의 핵심 구성 요소
RAG prompt는 보통 다음 요소를 포함합니다.
역할: 당신은 사내 문서를 기반으로 답변하는 AI 어시스턴트입니다.
지시: 제공된 context만 사용해 답변하세요.
질문: 사용자의 질문
context: 검색된 문서 chunk
출력 형식: 요약, 절차, 표, 주의사항 등
제약 조건: 모르면 모른다고 답하세요. 출처를 표시하세요.이 구조를 명확히 해두면 LLM이 검색 결과를 더 안정적으로 사용할 수 있습니다.
Context Grounding 지시
RAG에서 중요한 것은 LLM이 자기 지식이 아니라 검색된 context를 근거로 답변하도록 만드는 것입니다.
예를 들어 다음과 같은 지시가 필요할 수 있습니다.
제공된 context에 있는 정보만 사용해 답변하세요.
context에서 확인되지 않는 내용은 추측하지 마세요.
정보가 부족하면 어떤 정보가 부족한지 설명하세요.이런 지시는 hallucination을 줄이는 데 도움이 됩니다.
답변 형식 제어
사용자의 질문 유형에 따라 답변 형식을 지정하면 더 유용한 결과를 얻을 수 있습니다.
예를 들어 절차를 묻는 질문에는 다음 형식이 적합합니다.
1. 원인
2. 확인 방법
3. 해결 절차
4. 주의 사항비교 질문에는 표가 적합할 수 있습니다.
| 항목 | A 기능 | B 기능 |
|---|---|---|정책 질문에는 근거와 예외 사항을 분리하는 형식이 좋습니다.
Prompt Engineering은 단순히 문장을 예쁘게 만드는 것이 아니라, 검색된 정보를 사용자가 이해하기 좋은 답변으로 변환하는 설계 작업입니다.
4. LLM Fine-tuning: 도메인에 맞게 생성 모델 조정하기
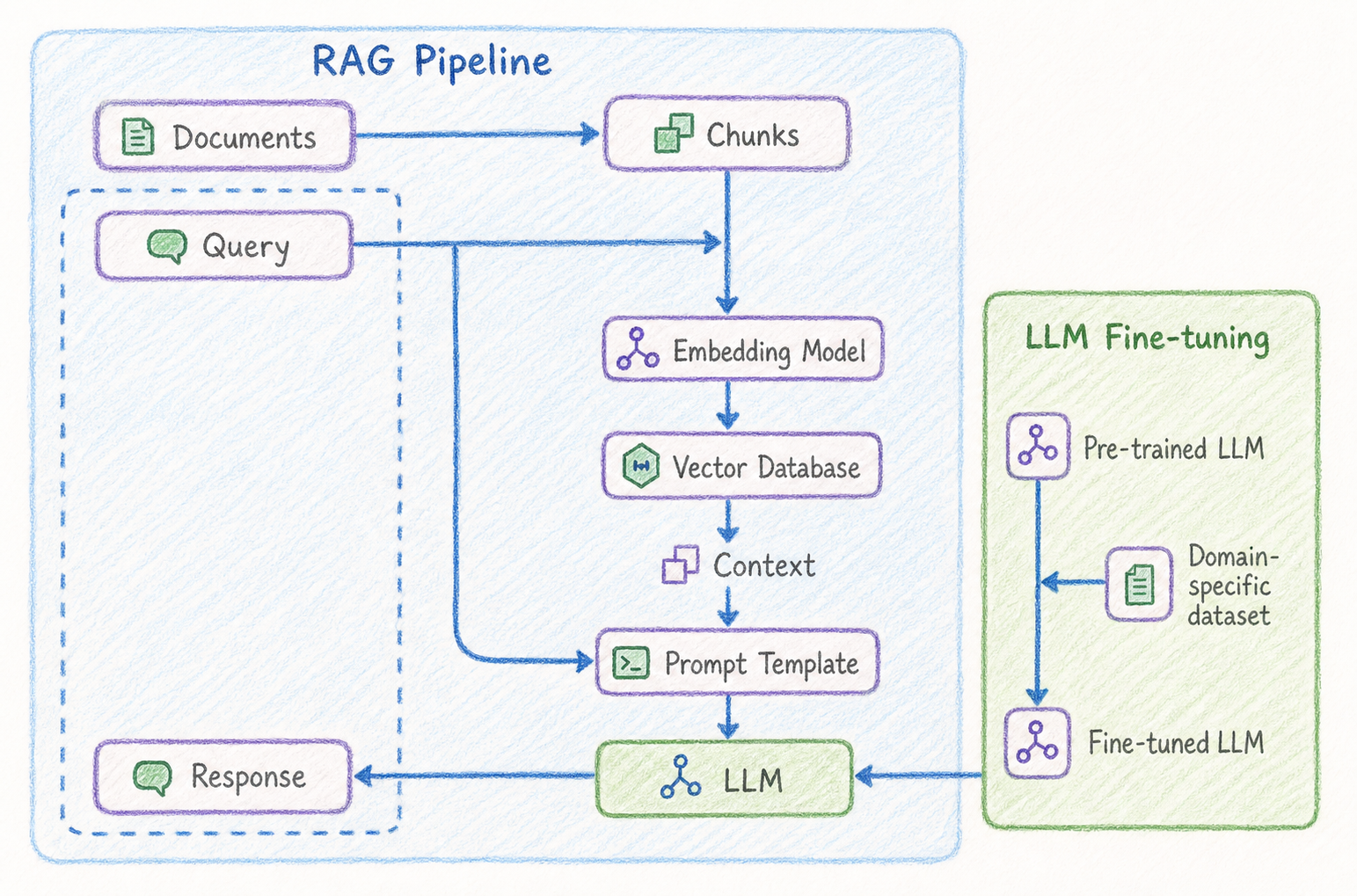
LLM Fine-tuning은 RAG 파이프라인에서 사용하는 생성 모델을 특정 도메인이나 업무 방식에 맞게 조정하는 방법입니다.
RAG는 외부 지식을 검색해 사용하는 방식이므로, 모든 지식을 LLM에 학습시킬 필요는 없습니다. 하지만 특정 도메인의 답변 스타일, 용어 사용, 출력 형식, 판단 기준을 모델이 더 잘 따르도록 만들고 싶다면 fine-tuning을 고려할 수 있습니다.
LLM Fine-tuning이 유용한 경우
LLM Fine-tuning은 다음 상황에서 유용할 수 있습니다.
- 특정 산업 용어를 일관되게 사용해야 할 때
- 답변 형식이 매우 엄격해야 할 때
- 고객 응대 톤이나 사내 문체를 맞춰야 할 때
- 검색된 context를 해석하는 방식에 도메인 규칙이 필요할 때
- 반복적으로 같은 유형의 답변을 생성해야 할 때
예를 들어 고객지원 RAG에서는 답변을 항상 다음 구조로 생성해야 할 수 있습니다.
문제 요약
원인
해결 방법
추가 확인 사항
고객 안내 문구이런 형식을 일관되게 유지하려면 prompt만으로도 가능하지만, 대규모 운영 환경에서는 fine-tuning이 도움이 될 수 있습니다.
LLM Fine-tuning의 주의점
Fine-tuning은 비용과 관리 부담이 큽니다. 또한 지식을 최신 상태로 유지하기 위한 방법으로 fine-tuning을 사용하는 것은 적절하지 않을 수 있습니다.
정책 문서나 제품 문서처럼 자주 바뀌는 지식은 RAG의 retrieval 영역에서 관리하는 것이 더 적합합니다. Fine-tuning은 최신 지식을 주입하는 목적보다, 모델의 행동 방식과 답변 스타일을 조정하는 목적으로 이해하는 것이 좋습니다.
Post-retrieval Optimization 전략 비교
| 전략 | 핵심 역할 | 장점 | 주의점 | 적합한 경우 |
|---|---|---|---|---|
| Re-ranking | 검색 결과 순서를 재정렬합니다 | 상위 결과의 관련성을 높입니다 | 초기 검색 후보에 정답이 있어야 효과적입니다 | 후보는 있지만 순서가 아쉬운 경우 |
| Context Post-processing | context를 정리하고 압축합니다 | 토큰 비용을 줄이고 핵심 정보에 집중합니다 | 중요한 근거가 삭제되지 않도록 해야 합니다 | 중복, 긴 문서, noisy context |
| Prompt Engineering | LLM이 context를 잘 쓰도록 지시합니다 | 답변 품질과 형식을 안정화합니다 | prompt가 복잡해지면 관리가 필요합니다 | 대부분의 RAG 시스템 |
| LLM Fine-tuning | 생성 모델을 도메인에 맞게 조정합니다 | 답변 스타일과 형식을 일관화합니다 | 비용과 운영 부담이 큽니다 | 고정된 형식, 도메인 특화 답변 |
Post-retrieval Optimization을 설계할 때의 체크리스트
Post-retrieval Optimization을 설계할 때는 다음 질문을 확인하는 것이 좋습니다.
Re-ranking
- 검색 결과의 상위 순서가 실제 관련성과 일치하나요?
- 정답 chunk가 검색되지만 아래쪽에 밀려 있나요?
- re-ranking을 적용할 후보 개수는 몇 개가 적절한가요?
- latency 증가를 감당할 수 있나요?
Context Post-processing
- 검색 결과에 중복 chunk가 많나요?
- context가 너무 길어 LLM 입력 토큰을 낭비하고 있나요?
- 질문과 직접 관련 없는 문장이 많이 포함되어 있나요?
- 최신 문서와 오래된 문서가 충돌하지 않나요?
- 출처 정보가 context와 함께 유지되나요?
Prompt Engineering
- LLM이 반드시 context 기반으로 답변하도록 지시되어 있나요?
- 모르는 내용은 모른다고 답하도록 되어 있나요?
- 답변 형식이 질문 유형에 맞게 정의되어 있나요?
- 출처나 근거를 표시해야 하나요?
LLM Fine-tuning
- prompt만으로 해결하기 어려운 일관성 문제가 있나요?
- 답변 형식이나 톤이 매우 엄격한가요?
- fine-tuning 데이터셋을 충분히 확보했나요?
- 지식 업데이트는 retrieval로 관리하고 있나요?
예시: 고객지원 RAG에서 Post-retrieval Optimization 적용하기
고객지원 RAG 챗봇이 다음 질문을 받았다고 가정해보겠습니다.
SSO 로그인 오류가 발생했는데 어떻게 안내해야 하나요?Retrieval 단계에서는 다음과 같은 chunk가 검색될 수 있습니다.
1. SSO 설정 개요
2. SAML 인증 오류 해결 방법
3. 일반 로그인 오류 FAQ
4. 관리자 계정 권한 설정
5. 고객 안내 템플릿이 결과를 그대로 LLM에 넣는 대신 post-retrieval 단계를 적용할 수 있습니다.
먼저 Re-ranking을 통해 "SAML 인증 오류 해결 방법”과 "고객 안내 템플릿”을 상위로 올립니다.
그다음 Context Post-processing을 통해 중복 설명을 제거하고, 실제 답변에 필요한 부분만 남깁니다.
- 오류 원인 후보
- 고객에게 확인 요청할 항목
- 해결 절차
- 고객 안내 문구마지막으로 Prompt Engineering을 적용해 다음 형식으로 답변하도록 지시합니다.
1. 문제 요약
2. 고객에게 확인할 항목
3. 안내할 해결 절차
4. 추가 조치가 필요한 경우이렇게 하면 검색 결과를 단순히 나열하는 답변이 아니라, 고객지원 담당자가 바로 사용할 수 있는 형태의 답변을 만들 수 있습니다.
Post-retrieval Optimization의 한계
Post-retrieval Optimization은 검색 결과를 더 잘 활용하도록 도와주지만, 검색 자체의 실패를 완전히 해결하지는 못합니다.
초기 retrieval 단계에서 관련 문서가 아예 검색되지 않았다면 re-ranking이나 context 정리만으로는 정답을 만들기 어렵습니다. 또한 context 압축 과정에서 중요한 정보가 빠지면 오히려 답변 품질이 낮아질 수 있습니다.
Prompt Engineering도 만능은 아닙니다. prompt가 길고 복잡해지면 유지보수가 어려워지고, 모델이나 문서 유형이 바뀔 때 다시 조정해야 할 수 있습니다.
LLM Fine-tuning 역시 비용과 데이터 준비가 필요하기 때문에 신중하게 선택해야 합니다.
따라서 Post-retrieval Optimization은 단독으로 보기보다, indexing, pre-retrieval, retrieval 단계와 함께 전체 RAG 파이프라인 관점에서 설계하는 것이 좋습니다.
마치며: 검색된 정보를 답변 가능한 context로 바꾸는 단계입니다
Post-retrieval Optimization은 검색 결과를 LLM이 더 잘 사용할 수 있도록 정리하는 과정입니다.
검색 결과를 그대로 LLM에 넣는 것은 간단하지만, 항상 좋은 선택은 아닙니다. 실제 RAG 시스템에서는 검색된 chunk를 다시 정렬하고, 중복을 제거하고, 필요한 정보만 압축하고, prompt를 통해 LLM의 사용 방식을 명확히 지시해야 합니다.
핵심은 다음과 같습니다.
- Re-ranking은 검색 결과의 순서를 다시 조정해 관련성이 높은 chunk를 앞에 배치합니다.
- Context Post-processing은 중복과 노이즈를 줄이고 핵심 정보를 정리합니다.
- Prompt Engineering은 LLM이 검색된 context를 올바르게 사용하도록 안내합니다.
- LLM Fine-tuning은 답변 스타일과 도메인 규칙을 더 일관되게 반영하도록 돕습니다.
결국 Post-retrieval Optimization은 "검색된 정보”를 "답변 가능한 context”로 바꾸는 단계입니다. 좋은 RAG는 문서를 잘 찾는 것에서 끝나지 않고, 찾은 정보를 LLM이 가장 잘 활용할 수 있는 형태로 전달하는 것까지 포함합니다.
'AI' 카테고리의 다른 글
| 지구상에서 가장 친절한 RAG 06: 조직에서 RAG를 도입할 때 자주 묻는 질문들 (0) | 2026.06.03 |
|---|---|
| 지구상에서 가장 친절한 RAG 04: 더 좋은 근거를 찾는 검색 전략 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 03: 검색 전에 질문을 최적화하는 방법 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 02: 청킹 전략은 왜 중요한가 (0) | 2026.06.03 |
| 지구상에서 가장 친절한 RAG 01: 데이터 전처리가 검색 품질을 결정하는 이유 (0) | 2026.06.03 |